오늘은 저의 학위논문 CODE를 올려봅니다.
논문 분야는 텍스트 마이닝으로, 크게 감성분석, 토픽모델링, 대응분석으로 구성됩니다.
대응분석은 SAS로 수행했고 감성분석, 토픽모델링은 Google Colab 환경에서 Python 3.0으로 진행했습니다.
당시 학위논문을 쓰면서 텍스트 마이닝에 흥미를 더욱 가지며 졸업 후, Word Embedding과 Deep Learning으로 공부 영역을 확장했습니다. 현재도, 텍스트 마이닝, NLP 는 가장 관심있는 분야입니다.
그럼, 토픽모델링 CODE를 올려보도록 하겠습니다.
목차
1. 데이터 불러오기 및 형태소 분석
2. 단어 전처리
2.1. 형태소 분석에서 분할된 단어 하나로 합치기
2.2. 너무 많이 나오는 단어 제거하기
2.3. 의미없는 단어 제거 및 한 글자인 경우 제거하기
3. 기사별로 단어들을 합치기
4. 빈도수가 높은 단어, 너무 낮은 단어 제거하기
5. Gensim 패키지를 이용해 토픽모델링하기
5.1. 토픽수 구하기
5.2. 토픽모델링하기
5.3. 기사별 토픽 할당하기
1. 데이터 불러오기 및 형태소 분석
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
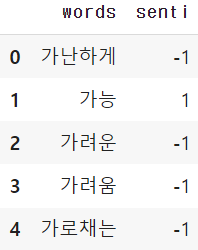
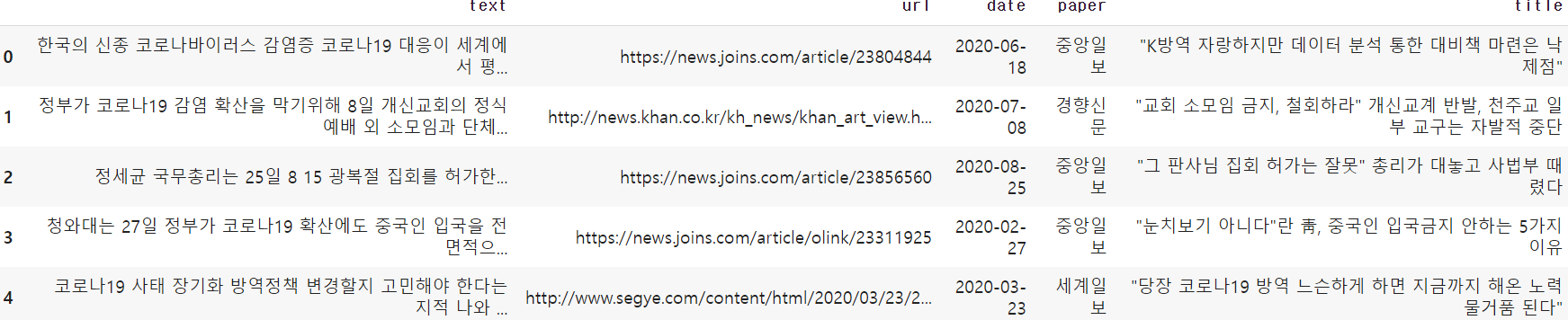
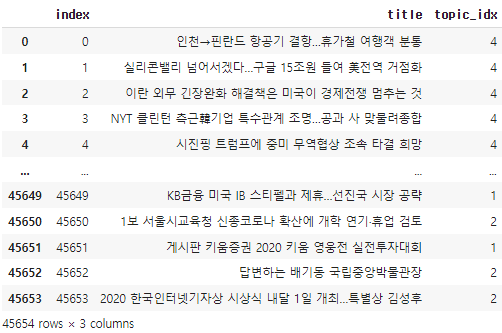
link = pd.read_excel('/content/drive/MyDrive/방역 기사 추출.xlsx')
link.head()
#한글제외 제거
import re
hangul = re.compile('[^ ㄱ-ㅣ가-힣]+') # 한글과 띄어쓰기를 제외한 모든 글자
for i in range(len(link)):
link.iloc[i,0] = hangul.sub(' ', link.iloc[i,0]) # 한글과 띄어쓰기를 제외한 모든 부분을 제거
#Komoran 이용하여 형태소 분석 수행
!apt-get update
!apt-get install g++ openjdk-8-jdk python-dev python3-dev
!pip3 install JPype1-py3
!pip3 install konlpy
!JAVA_HOME="C:\Users\tyumi\Downloads"
from konlpy.tag import * # class
komoran=Komoran()
for i in range(0,len(link)):
link.iloc[i,0]=re.sub('\n|\r','',link.iloc[i,0])
text_1=[]
article=[]
index=[]
paper=[]
title=[]
date=[]
for j in range(0,len(link)):
ex_pos=list(komoran.pos(link.iloc[j,0]))
for (text, tclass) in ex_pos : # ('형태소', 'NNG')
if tclass == 'VA' or tclass == 'NNG' or tclass == 'NNP' or tclass == 'MAG' :
text_1.append(text)
index+=[j]
article+=[link.iloc[j,0]]
paper+=[link.iloc[j,3]]
title+=[link.iloc[j,4]]
date+=[link.iloc[j,2]]
link=pd.DataFrame({'Index':index,'Phrase':text_1,'Text':article,'Paper':paper,'Title':title,'Date':date})
2. 단어 전처리
2.1. 형태소 분석에서 분할된 단어 하나로 합치기
for i in range(0,len(link)):
if str(link.iloc[i,1])=='코로나':
if str(link.iloc[i+1,1])=='바이러스':
link.iloc[i,1]=''
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='미래':
if str(link.iloc[i+1,1])=='통합':
if str(link.iloc[i+2,1])=='당':
link.iloc[i,1]='미래통합당'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='자유':
if str(link.iloc[i+1,1])=='한국당':
link.iloc[i,1]='자유한국당'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='사회':
if str(link.iloc[i+1,1])=='거리':
if str(link.iloc[i+2,1])=='두기':
link.iloc[i,1]='거리두기'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='거리':
if str(link.iloc[i+1,1])=='두기':
link.iloc[i,1]='거리두기'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='중앙':
if str(link.iloc[i+1,1])=='방역':
if str(link.iloc[i+2,1])=='대책':
if str(link.iloc[i+3,1])=='본부':
link.iloc[i,1]=''
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
link.iloc[i+3,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='보건':
if str(link.iloc[i+1,1])=='복지':
if str(link.iloc[i+2,1])=='가족부':
link.iloc[i,1]=''
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='보건':
if str(link.iloc[i+1,1])=='복지부':
link.iloc[i,1]='보건복지부'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='박':
if str(link.iloc[i+1,1])=='능':
if str(link.iloc[i+2,1])=='후':
link.iloc[i,1]='박능후'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='정은':
if str(link.iloc[i+1,1])=='경':
link.iloc[i,1]='정은경'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='문':
if str(link.iloc[i+1,1])=='대통령':
link.iloc[i,1]='문재인'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='공공':
if str(link.iloc[i+1,1])=='의대':
link.iloc[i,1]='공공의대'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='공공':
if str(link.iloc[i+1,1])=='의료':
link.iloc[i,1]='공공의료'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='소상':
if str(link.iloc[i+1,1])=='공인':
link.iloc[i,1]='소상공인'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='자가':
if str(link.iloc[i+1,1])=='격리':
link.iloc[i,1]='자가격리'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='자가':
if str(link.iloc[i+1,1])=='진단':
link.iloc[i,1]='자가진단'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='사랑':
if str(link.iloc[i+1,1])=='제일':
if str(link.iloc[i+2,1])=='교회':
link.iloc[i,1]='사랑제일교회'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='세계':
if str(link.iloc[i+1,1])=='보건':
if str(link.iloc[i+2,1])=='기구':
link.iloc[i,1]='세계보건기구'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='박':
if str(link.iloc[i+1,1])=='시장':
link.iloc[i,1]='박원순'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='우':
if str(link.iloc[i+1,1])=='한':
link.iloc[i,1]='우한'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='강':
if str(link.iloc[i+1,1])=='대변인':
link.iloc[i,1]='강경화'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='한국':
if str(link.iloc[i+1,1])=='발':
link.iloc[i,1]='한국발'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='검':
if str(link.iloc[i+1,1])=='체':
link.iloc[i,1]='검체'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='강경':
if str(link.iloc[i+1,1])=='외교부':
if str(link.iloc[i+2,1])=='장관':
link.iloc[i,1]='강경화'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
elif str(link.iloc[i+1,1])=='외교':
if str(link.iloc[i+2,1])=='장관':
link.iloc[i,1]='강경화'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
elif str(link.iloc[i+1,1])=='장관':
link.iloc[i,1]='강경화'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='국':
if str(link.iloc[i+1,1])=='격':
link.iloc[i,1]='국격'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='차':
if str(link.iloc[i+1,1])=='벽':
link.iloc[i,1]='차벽'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='중국':
if str(link.iloc[i+1,1])=='발':
link.iloc[i,1]='중국발'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='국민':
if str(link.iloc[i+1,1])=='힘':
link.iloc[i,1]='국민의힘'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='개천절':
if str(link.iloc[i+1,1])=='집회':
link.iloc[i,1]='개천절집회'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='광화문':
if str(link.iloc[i+1,1])=='집회':
link.iloc[i,1]='광화문집회'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='엄마':
if str(link.iloc[i+1,1])=='부대':
link.iloc[i,1]='엄마부대'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='전광훈':
if str(link.iloc[i+1,1])=='목사':
link.iloc[i,1]='전광훈목사'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='베이':
link.iloc[i,1]='후베이'
elif str(link.iloc[i,1])=='신천지예수교':
link.iloc[i,1]='신천지'
elif str(link.iloc[i,1])=='민주당':
link.iloc[i,1]='더불어민주당'
elif str(link.iloc[i,1])=='신천지예수교 증거장막성전':
link.iloc[i,1]='신천지'
elif str(link.iloc[i,1])=='의과대학':
link.iloc[i,1]='의대'
elif str(link.iloc[i,1])=='대한의사협회':
link.iloc[i,1]='의협'
elif str(link.iloc[i,1])=='중동호흡기증후군':
link.iloc[i,1]='메르스'
elif str(link.iloc[i,1])=='비대':
link.iloc[i,1]='비대면'
elif str(link.iloc[i,1])=='우하':
link.iloc[i,1]='우한'2.2. 너무 많이 나오는 단어 제거하기
for i in range(0,len(link)):
if str(link.iloc[i,1])=='뉴시스':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='국민일보':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='연합뉴스':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='중대본':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='질본':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='질병관리본부':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='질병관리본부장':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='코로나바이러스':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='코로나':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='신종':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='이날':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='기자':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='매일일보':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='의원':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='대표':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='장관':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='총리':
link.iloc[i,1]=''
elif str(link.iloc[i,1])=='위원장':
link.iloc[i,1]=''2.3. 의미없는 단어 제거 및 한 글자인 경우 제거하기
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
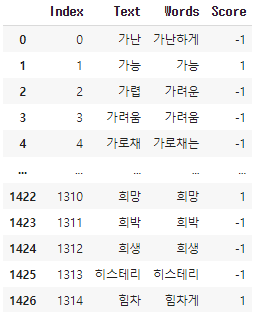
dd = pd.read_excel('/content/drive/MyDrive/제거문자.xlsx')
def find_index(data, target):
res = []
lis = data
while True:
try:
res.append(lis.index(target) + (res[-1]+1 if len(res)!=0 else 0)) #+1의 이유 : 0부터 시작이니까
lis = data[res[-1]+1:]
except:
break
return res
aa=[]
for i in range(0,len(dd)):
aa+=find_index(link.iloc[:,1].tolist(),dd.iloc[i,0])
for j in range(0,len(aa)):
link.iloc[aa[j],1]=''
ii=[]
for i in range(0,len(link)):
if link.iloc[i,1]!='':
ii+=[i]
link_1=link.iloc[ii,:]
for i in range(0,len(link_1)):
if len(link_1.iloc[i,1])==1:
link_1.iloc[i,1]=''
ii=[]
for i in range(0,len(link_1)):
if link_1.iloc[i,1]!='':
ii+=[i]
link_2=link_1.iloc[ii,:]
link_2
3. 기사별로 단어들을 합치기
!pip3 install gensim
import gensim
link_2=link_2.reset_index(drop=True)
grouped =link_2.groupby(['Index'])
for key, group in grouped:
globals()['Phrase_{}'.format(key)]=list(group.Phrase)
globals()['Index_{}'.format(key)]=list(group.Index)[0]
globals()['Text_{}'.format(key)]=list(group.Text)[0]
globals()['Title_{}'.format(key)]=list(group.Title)[0]
globals()['Paper_{}'.format(key)]=list(group.Paper)[0]
globals()['Date_{}'.format(key)]=list(group.Date)[0]
Phrase=[]
Index=[]
Text=[]
Title=[]
Paper=[]
Date=[]
for key in range(470):
Phrase.append(globals()['Phrase_{}'.format(key)])
Index.append(globals()['Index_{}'.format(key)])
Text.append(globals()['Text_{}'.format(key)])
Title.append(globals()['Title_{}'.format(key)])
Paper.append(globals()['Paper_{}'.format(key)])
Date.append(globals()['Date_{}'.format(key)])
link_3=pd.DataFrame({'Index':Index,'Phrase':Phrase,'Text':Text,'Title':Title,'Paper':Paper,'Date':Date})
link_3
4. 빈도수가 높은 단어, 너무 낮은 단어 제거하기
from gensim import corpora
tokenized_doc = link_3.Phrase
dictionary = corpora.Dictionary(tokenized_doc)
dictionary.filter_extremes(no_below=5,no_above=0.8)
text=tokenized_doc
corpus = [dictionary.doc2bow(text) for text in tokenized_doc]5. Gensim 패키지를 이용해 토픽모델링하기
5.1. 토픽수 구하기
#토픽모델링-토픽수
per=[]
import matplotlib.pyplot as plt
from gensim import models
for i in range(1,11):
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = i, id2word=dictionary, passes=500,random_state=2500,gamma_threshold=0.01,alpha='auto')
cm = models.CoherenceModel(model=ldamodel, corpus=corpus, coherence='u_mass')
coherence = cm.get_coherence()
per.append(coherence)
limit=11; start=1; step=1;
x = range(start, limit, step)
plt.plot(x, per)
plt.xlabel("Num Topics")
plt.ylabel("Coherence score")
plt.legend(("per"), loc='best')
plt.show()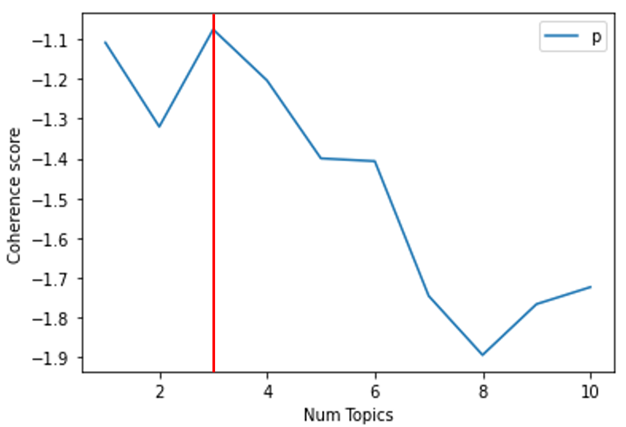
5.2. 토픽모델링하기
NUM_TOPICS = 3
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = NUM_TOPICS, id2word=dictionary, passes=500,random_state=2500,gamma_threshold=0.01,alpha='auto')
topics = ldamodel.print_topics(num_words=20)
for topic in topics:
print(topic)5.3. 기사별 토픽 할당하기
#토픽모델링-문서
def make_topictable_per_doc(ldamodel, corpus):
topic_table = pd.DataFrame()
for i, topic_list in enumerate(ldamodel[corpus]):
doc = topic_list[0] if ldamodel.per_word_topics else topic_list
doc = sorted(doc, key=lambda x: (x[1]), reverse=True)
for j, (topic_num, prop_topic) in enumerate(doc):
if j == 0:
topic_table = topic_table.append(pd.Series([int(topic_num), round(prop_topic,4), topic_list]), ignore_index=True)
else:
break
return(topic_table)
topictable = make_topictable_per_doc(ldamodel, corpus)
topictable = topictable.reset_index()
a=topictable.iloc[:,0]
b=topictable.iloc[:,1]
c=topictable.iloc[:,2]
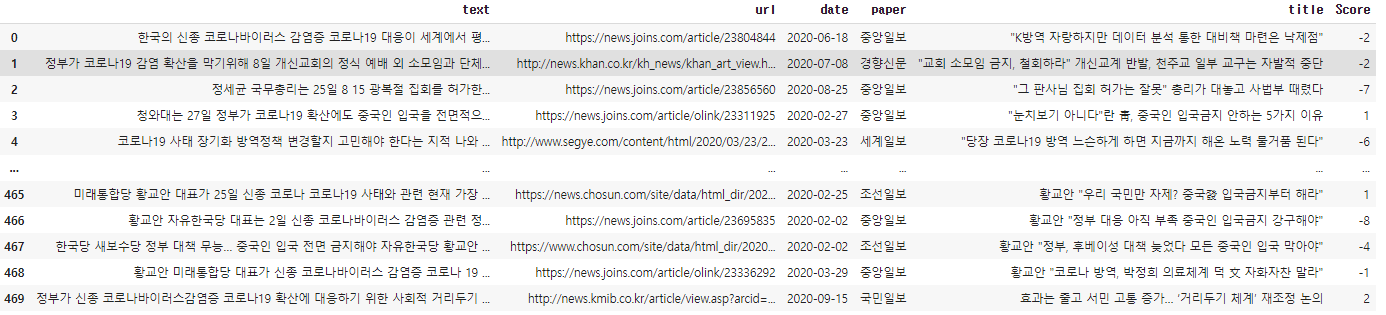
link_3['Topic']=b.tolist()
link_3['Frequency']=c.tolist()
6. 최종 결과
| 주제 | 주제명 | 주제비중 |
| 주제1 | 코로나 19 발생 초기 정부 대응에 대한 국내외 평가 | 50% |
| 주제2 | 코로나 19 장기화로 인한 정부의 방역 정책 논란 | 24% |
| 주제3 | 정부의 집회 대응에 대한 논란 | 26% |
'대회' 카테고리의 다른 글
| [학위논문] 대응 분석과 토픽 모델링을 이용한 언론사별 계층적 감성분석 - 감성분석 CODE (1) | 2022.01.12 |
|---|---|
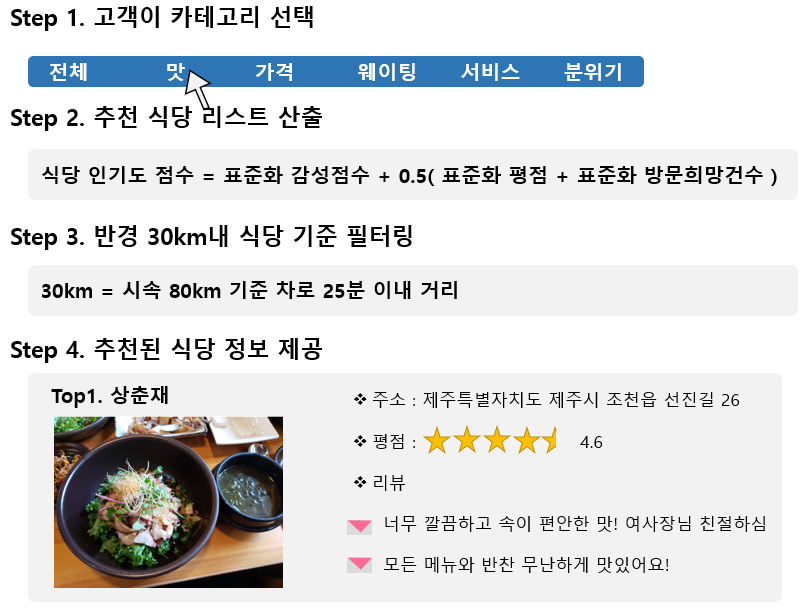
| 리뷰 기반 맛집 추천 시스템 [공모전 결과물]-I am yumida (10) | 2021.11.24 |
| Bi-LSTM 기법을 이용한 한국어 뉴스 토픽 분류[CODE] - I am yumida (0) | 2021.09.02 |