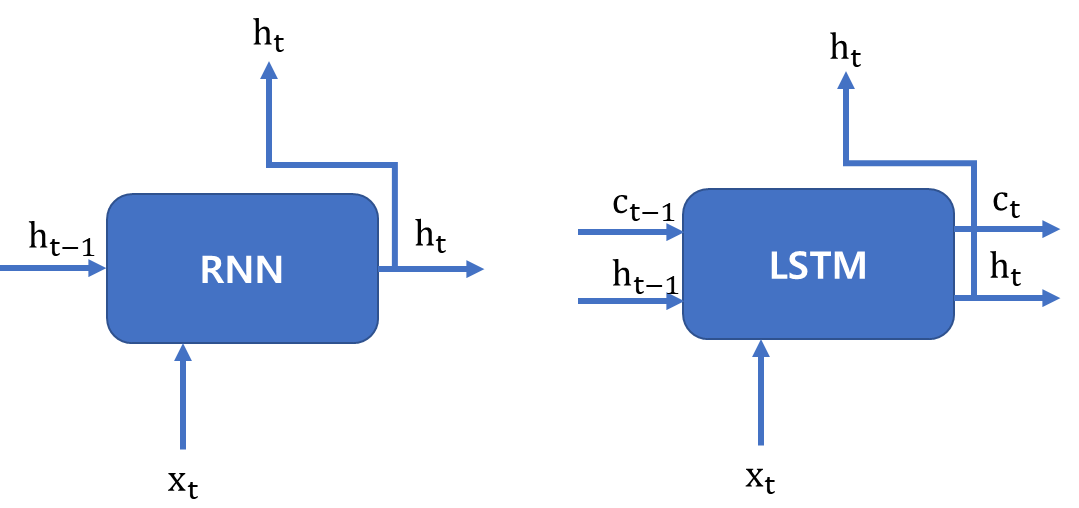
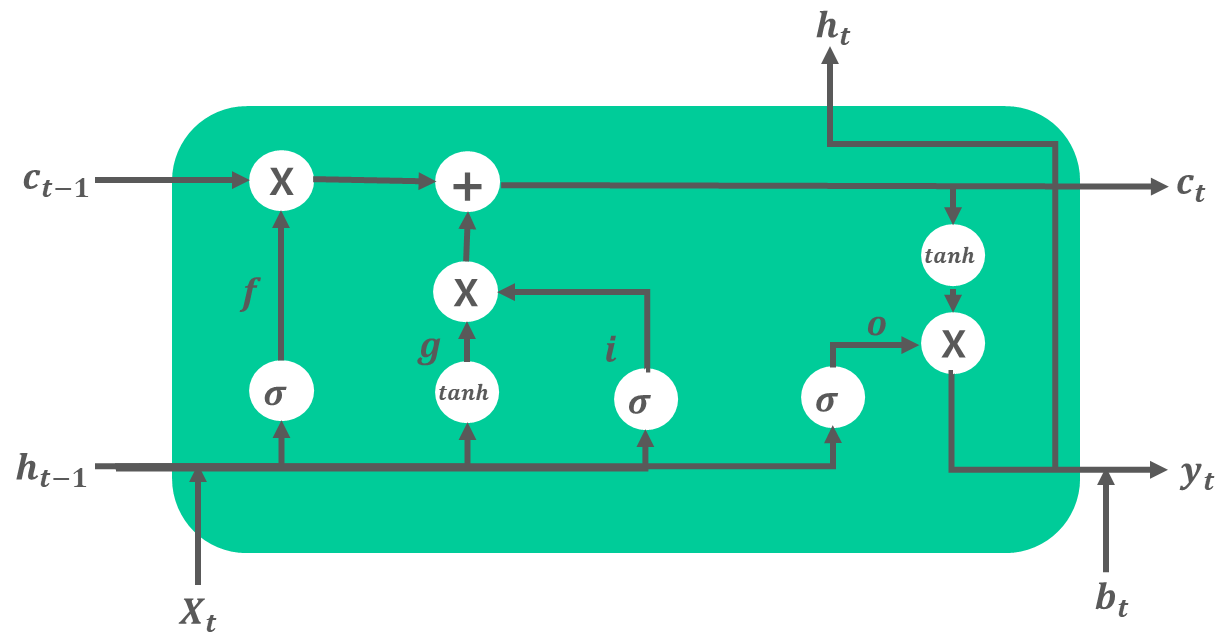
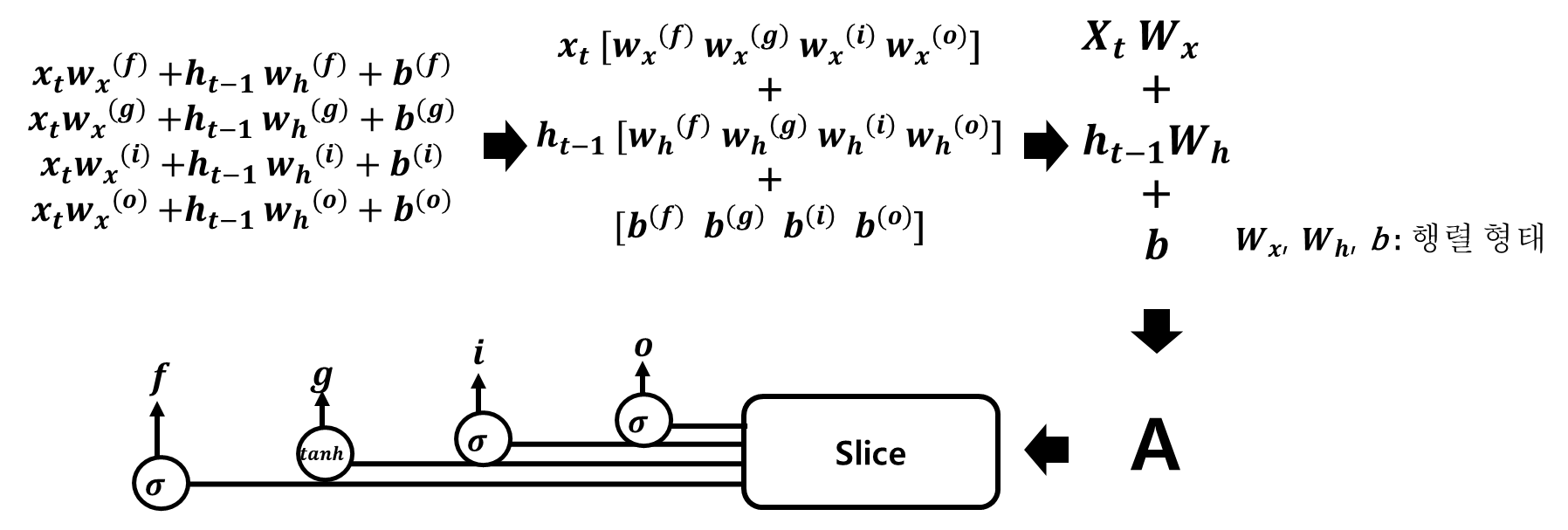
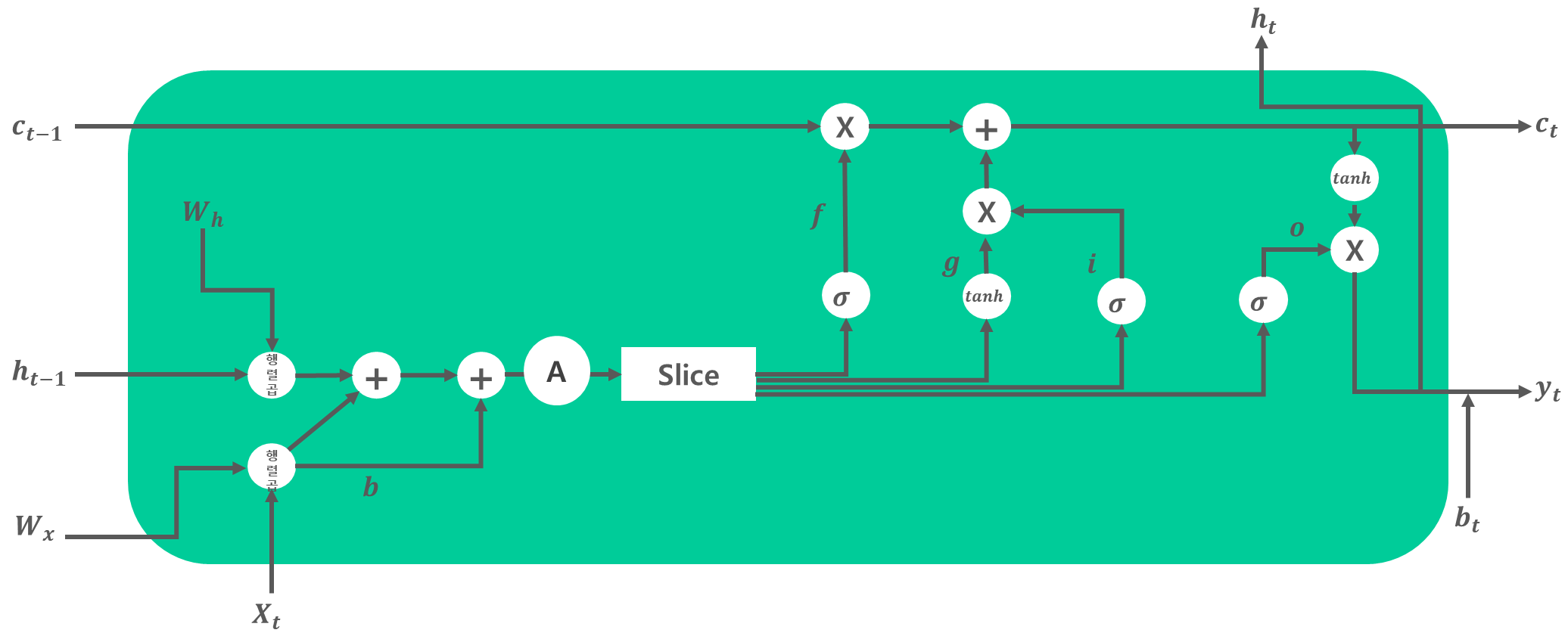
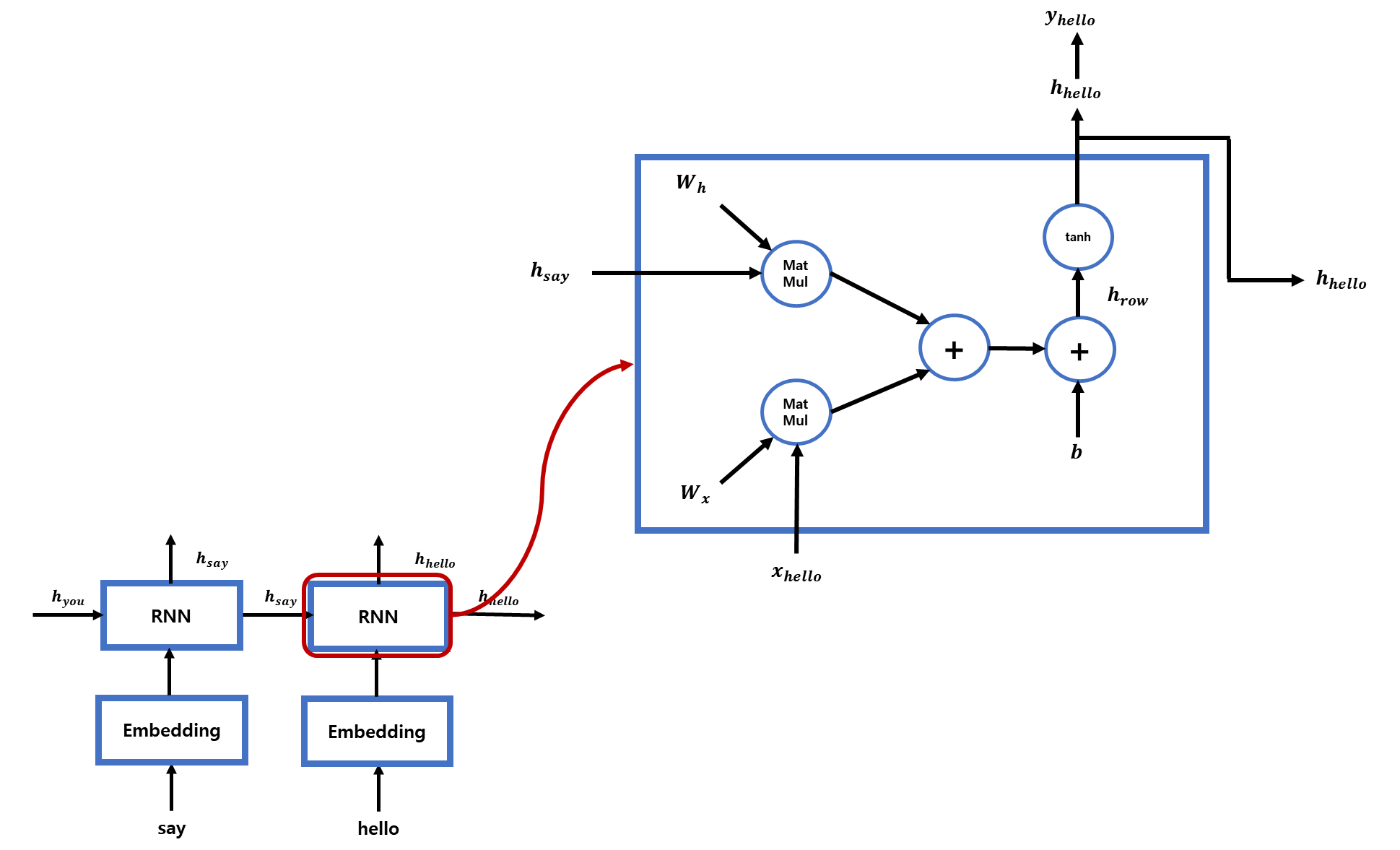
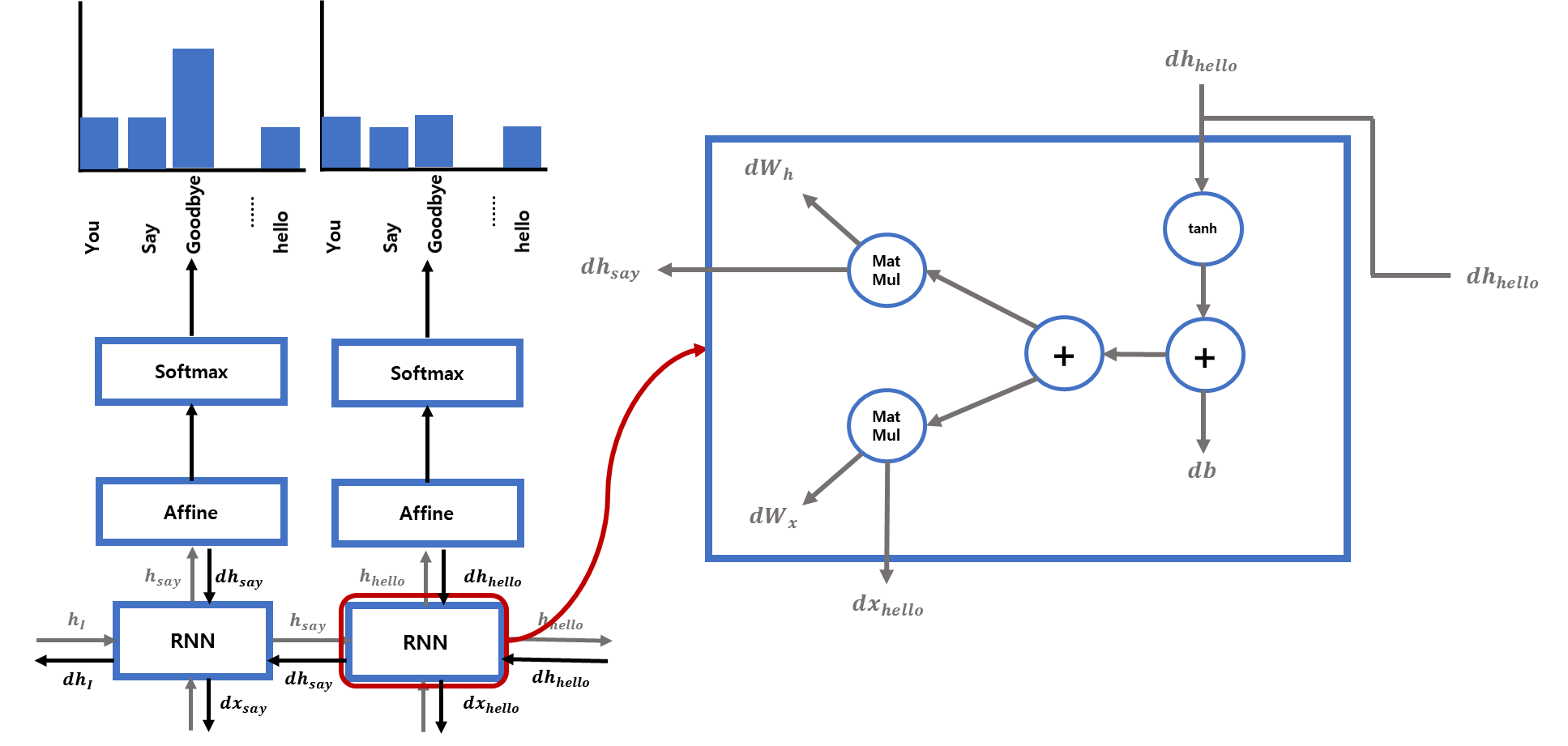
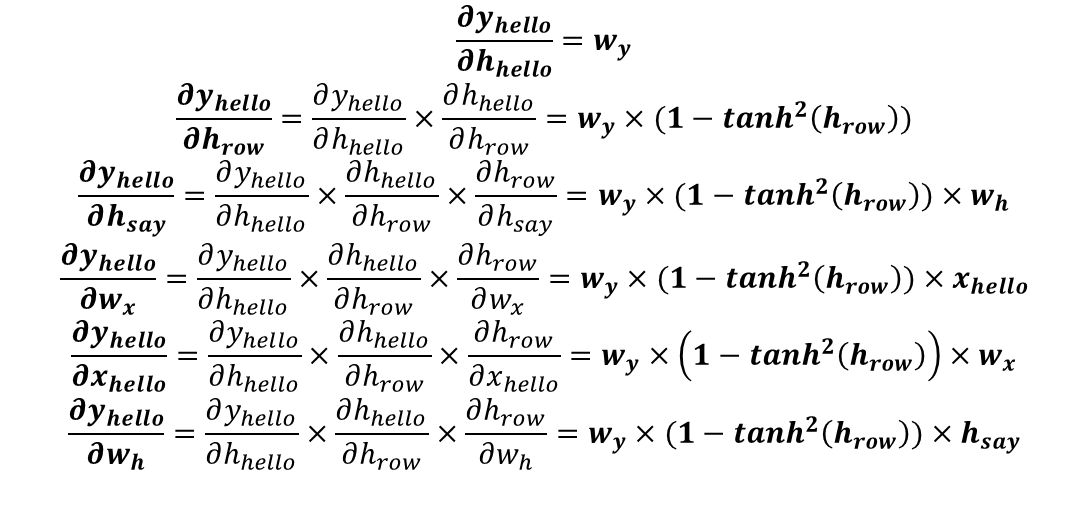
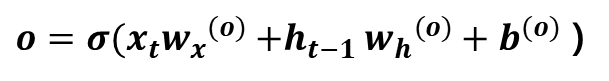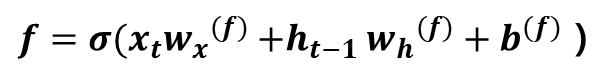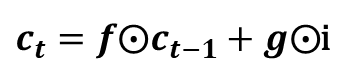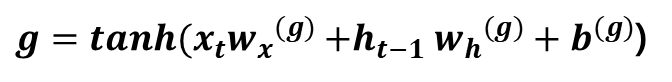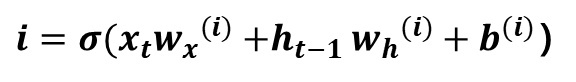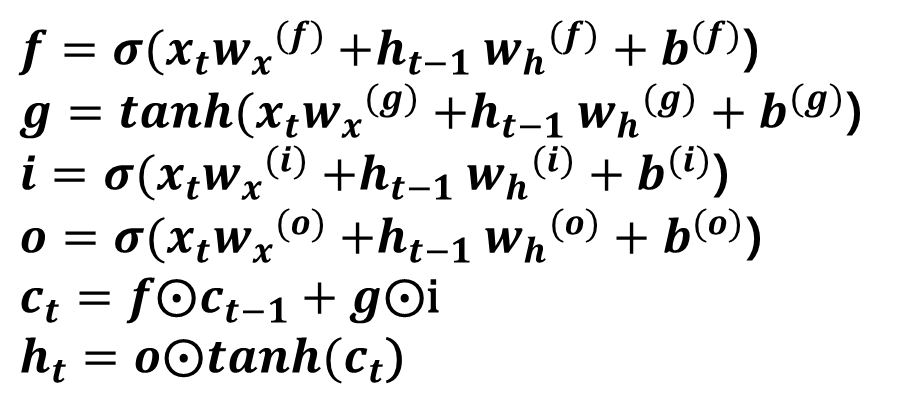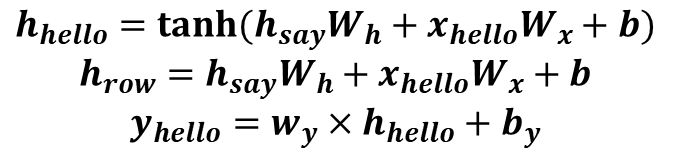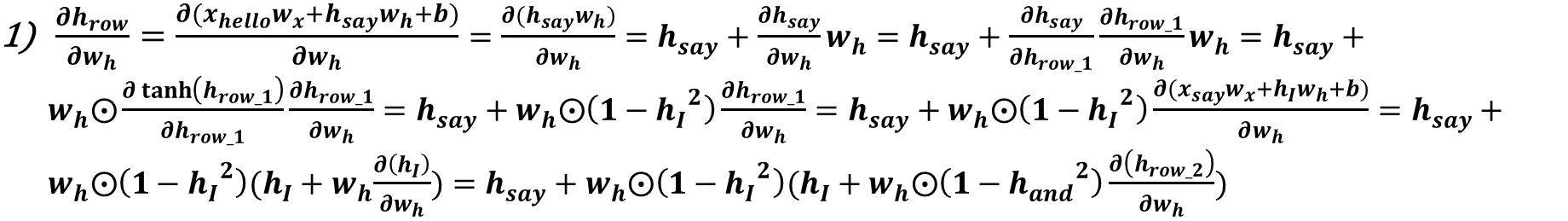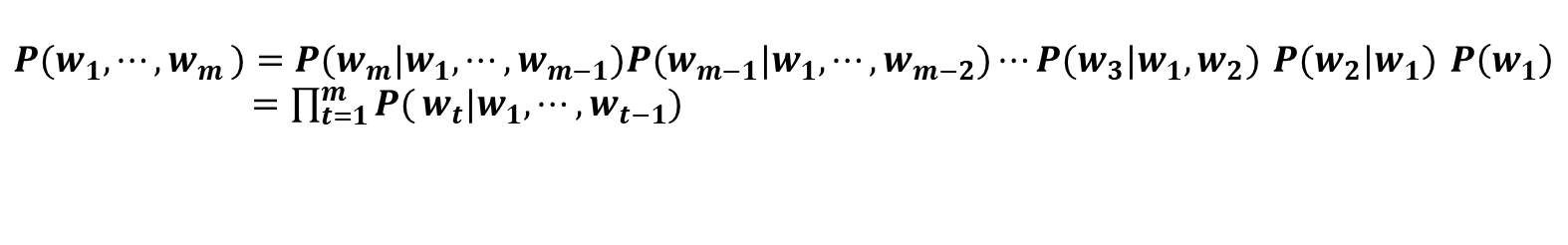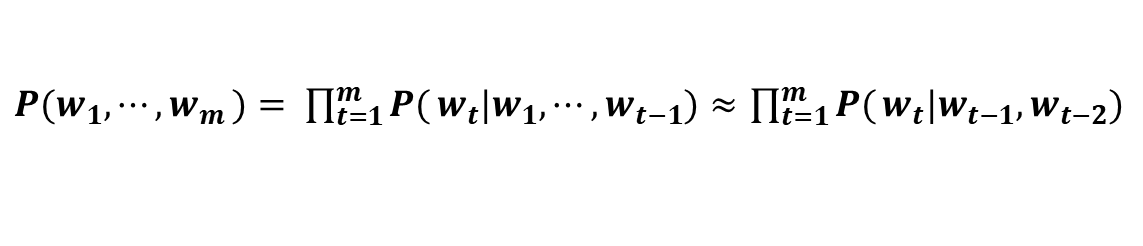이 게시글은 책 '구글 BERT의 정석'의 셀프어텐션 설명을 요약 및 정리했습니다.
http://www.yes24.com/Product/Goods/104491152
구글 BERT의 정석 - YES24
인간보다 언어를 더 잘 이해하고 구현하는 고성능 AI 언어 모델 BERT이 책은 자연어 응용 분야에서 상당한 성능 향상을 이뤄 주목받고 있는 BERT 모델을 기초부터 다양한 변형 모델, 응용 사례까지
www.yes24.com
오늘은 셀프 어텐션에 대하여 알아볼 것입니다.
셀프 어텐션은 트랜스포머를 구성하는 핵심 요소입니다.
셀프 어텐션 -> 멀티 헤드 어텐션 -> 트랜스포머 순서로 향후 게시글을 올릴 예정입니다.
셀프 어텐션이 무엇인지 예를 통해서 알아보고, 사용되는 주요 행렬을 알아본 후, 작동 원리를 설명하면서 마무리하겠습니다.
목차
1. 셀프 어텐션 감잡기
2. 셀프 어텐션에서 사용되는 주요 행렬
3. 셀프 어텐션의 작동 원리
1. 셀프 어텐션 감잡기
셀프 어텐션은 트랜스포머를 구성하는 핵심 요소로, 특수한 형태의 어텐션입니다.
아래와 같은 문장이 있다고 가정합시다.
A cat ate the fish because it was hungry.
이 문장에서 우리는 'it'은 'cat'을 가리킴을 알 수 있습니다. 위 문장에 셀프 어텐션을 적용한다면, 모델은 'it'이 'fish'보다 'cat'과 연관성이 큰 것을 알 수 있습니다. 왜냐하면 이 문장이 모델에 입력되었을 때, 모델이 'it'이라는 단어의 의미를 이해하기 위해 문장 안에 있는 모든 단어와 'it'이라는 단어의 관계를 계산하는 작업을 수행하기 때문입니다.
그림으로 표현하면 아래와 같습니다.

그림은 'it'이라는 단어의 표현을 계산하기 위해 'it'을 문장의 모든 단어와 연결하는 작업을 보여줍니다. 이와 같은 연결 작업으로 모델은 'it'이 'fish'보다 'cat'과 연관성이 큰 것을 학습합니다.
이렇게 작동하려면 무엇이 필요할까요? 셀프 어텐션에서 사용되는 주요 행렬에 대하여 알아봅시다.
2. 셀프 어텐션에서 사용되는 주요 행렬
문장을 셀프 어텐션에서 사용하려면 임베딩하는 작업이 필요합니다. 셀프 어텐션은 임베딩 된 벡터로부터 쿼리(Q) 행렬, 키(K) 행렬, 밸류(V) 행렬을 생성하고, 이 세 가지 행렬을 이용해서 작동합니다.
세 가지 행렬이 어떻게 만들어지는지 아래의 문장을 통해 설명드리겠습니다.
I am good
이 문장을 임베딩한 결과는 다음과 같습니다.
이 행렬을 X라고 하겠습니다. 행렬 X에서 첫 번째 행은 'I'의 임베딩, 두 번째 행은 'am'의 임베딩, 세 번째 행은 'good'의 임베딩을 의미합니다. 이때 X의 차원은 [문장 길이 x 임베딩 차원]의 형태입니다.
이렇게 임베딩 된 행렬로부터 세 개의 가중치 행렬을 행렬 X에 곱하면 쿼리 행렬, 키 행렬, 밸류 행렬이 계산됩니다. 여기서 세 개의 가중치 행렬은 처음에 임의의 값을 가지며, 학습 과정에서 최적의 값을 얻게 됩니다.
그림으로 표현하면 다음과 같습니다.
3. 셀프 어텐션의 작동원리
이제 쿼리, 키 밸류 행렬을 셀프 어텐션에 어떻게 사용하는지 보겠습니다.
셀프 어텐션은 총 4단계로 이루어져 있습니다.
1단계.
쿼리(Q) 행렬과 키(K) 행렬의 내적 연산을 수행합니다.
이를 해석하자면, Q와 K를 내적한 행렬(QK행렬)의 첫 번째 행은 쿼리 벡터1과 키 벡터 1, 2, 3의 내적을 계산한다는 것을 알 수 있습니다. 두 벡터 사이의 내적을 계산하면 두 벡터가 얼마나 유사한지를 알 수 있습니다. 즉, I의 쿼리 벡터와 I의 키 벡터, am의 키 벡터, good의 키 벡터 사이의 유사도를 계산한 것입니다.
QK행렬의 첫 번째 행은 110, 90, 80 입니다. 이를 통해 단어 I는 단어 am과 good보다 자신(I)과 연관성이 더 높은 것을 알 수 있습니다. 내적값이 110으로 첫번째 행에서 가장 높기 때문입니다.
2단계.
QK행렬의 키 벡터 차원의 제곱근값으로 나눕니다. 이렇게 하면, 안정적인 경사값을 얻을 수 있습니다.
키 벡터의 차원을 64라고 가정하면 이것의 제곱근인 8로 QK행렬을 나눕니다. 결과는 아래와 같습니다.

3단계.
이전 단계에서 계산한 유사도 값은 비정규화된 형태이기 때문에 소프트맥스 함수를 적용해 정규화 작업을 진행합니다.
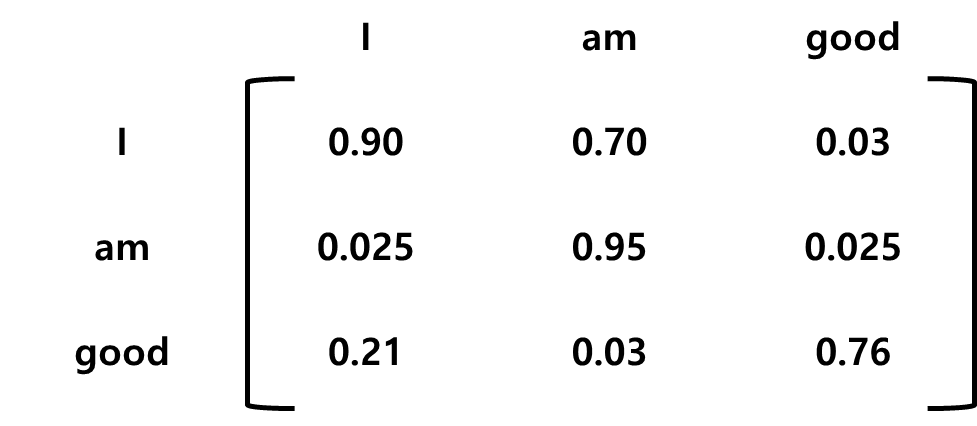
4단계.
앞에서 구한 행렬들을 이용하여 어텐션 행렬(Z)를 계산합니다. 어텐션 행렬은 문장의 각 단어의 벡터값을 갖습니다. 3단계에서 계산한 행렬에 밸류 행렬(V)를 곱하면 어텐션 행렬(Z)를 구할 수 있습니다.

Z를 구하면 단어 good의 셀프 어텐션 z3도 구할 수 있습니다.

z3는 밸류 벡터 v(I)의 0.21 비중, 벨류 벡터 v(am)의 0.03 비중, 벨류 벡터 v(good)의 0.76 비중의 합이라는 것을 알 수 있습니다. 이렇게 보면, 단어 good의 셀프 벡터값은 밸류 벡터 v(am)보다 v(I)가 많이 반영된 결과로 볼 수 있습니다. 이는 모델에서 good이 am이 아닌 I와 관련이 크다는 것을 알 수 있습니다. 셀프 어텐션 방법을 적용하면 이렇게 단어가 문장 내에 있는 다른 단어와 얼마나 연관성이 있는지를 알 수 있습니다.
정리하자면 다음과 같습니다.
1단계. 쿼리 행렬과 키 행렬 간의 내적을 계산하고 유사도를 구한다.
2단계. 1단계에서 구한 QK행렬을 키 행렬 차원의 제곱근으로 나눈다.
3단계. 2단계에서 구한 행렬에 소프트맥스 함수를 적용해 정규화 작업을 진행한다.
4단계. 마지막으로 밸류 행렬을 곱해 어텐션 행렬 Z를 산출한다.
'AI' 카테고리의 다른 글
| [LSTM] LSTM을 알아봅시다[밑바닥부터 시작하는 딥러닝2 참고]-I am yumida (0) | 2022.01.16 |
|---|---|
| [RNN] RNN을 알아봅시다[밑바닥부터 시작하는 딥러닝2 참고]-I am yumida (1) | 2022.01.16 |
| [RNN] RNN에 들어가기 전에..(밑바닥부터 시작하는 딥러닝2) - I am yumida (0) | 2021.12.30 |
| 경사하강법에 대하여 알아봅시다.(Do it! 딥러닝 입문 정리) - I am yumida (0) | 2021.08.18 |
| MNIST 데이터를 CNN에 적용하여 분류하기 - I am yumida (0) | 2021.08.12 |