이 게시글은 '밑바닥부터 시작하는 딥러닝2'을 공부한 내용 바탕으로 정리했습니다.
http://www.yes24.com/Product/Goods/72173703
밑바닥부터 시작하는 딥러닝 2 - YES24
직접 구현하면서 배우는 본격 딥러닝 입문서 이번에는 순환 신경망과 자연어 처리다! 이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데
www.yes24.com
RNN을 본격적으로 설명하기 전에 언어모델로서 RNN이 왜 필요한지 설명드리겠습니다.
1과 2에서 언어모델을 설명한 후, 3에서 언어모델로 적합한 기법이 RNN임을 강조하며 필요성을 설명드리겠습니다.
언어모델을 이미 아는 분이시면 3으로 바로 넘어가주세요 :)
순서는 아래와 같습니다.
1. 언어모델이란?
2. 수식으로 표현한 언어모델
3. 언어모델 관점, RNN의 필요성
1. 언어모델이란?
언어모델은 문장에 대해서, 그 문장이 얼마나 자연스러운지를 확률로 평가하는 것입니다.
예를 들면, '나는 학교에 간다'라는 문장에는 높은 확률을 출력하고 '나는 학교에 갈매기'에는 낮은 확률을 출력하는 것이 일종의 언어모델입니다.
언어모델은 기계번역과 음성인식에 대표적으로 이용됩니다. 하지만 새로운 문장을 생성하는 용도로도 사용할 수 있습니다. 왜냐하면 언어모델은 단어 순서가 얼마나 자연스러운지를 확률적으로 평가할 수 있기 때문입니다. 따라서 해당 확률분포에 따라 다음 순서에 올 적합한 단어를 샘플링할 수 있습니다.
이제 언어모델을 수식으로 설명하겠습니다.
2. 수식으로 표현한 언어모델
w1,...,wm이라는 m개의 단어로 된 문장이 있을 때, 단어가 w1,...,wm순서로 등장할 확률을 P(w1,...,wm)이라고 합니다.
이 확률은 동시확률이라고도 합니다. 우리는 이 확률을 구해서 문장의 자연스러운 정도를 계산합니다.
동시확률 P(w1,...,wm)은 사후 확률을 사용해 [식 1]과 같이 분해하여 쓸 수 있습니다. [식 1]의 사후확률은 타깃 단어보다 왼쪽에 있는 모든 단어를 조건으로 했을 때의 확률입니다. 이러한 사후확률을 총곱해서 나온 것이 언어모델의 동시확률입니다.
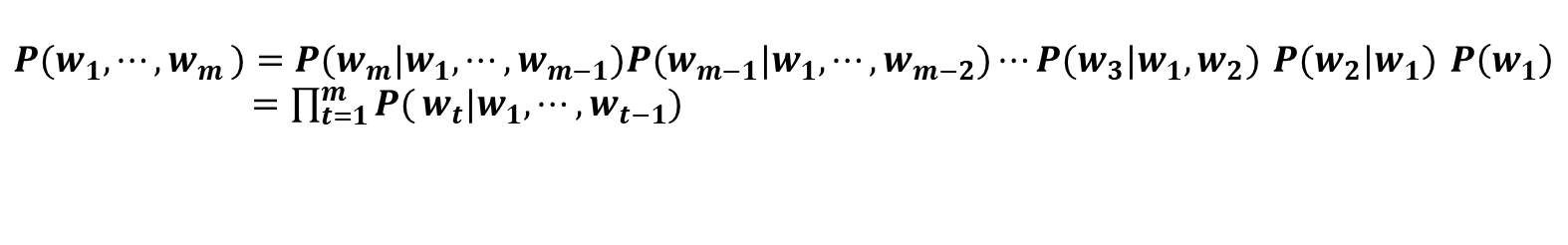
3. 언어모델 관점, RNN의 필요성
Word2Vec의 CBOW 모델을 언어 모델에 적용했을 때 나타나는 문제점(단어의 순서를 반영하지 않는 점)과 신경 확률론적 언어모델(NPLM)에서 제안한 모델의 문제점(단어가 늘어날수록 가중치가 증가하는 점)을 해결하기 위해 등장한 것이 RNN 언어모델입니다.
1) CBOW 모델을 이용한 언어모델
CBOW 모델을 억지로 언어모델에 적용하려면 맥락크기를 특정 값으로 한정하여 근사적으로 나타냅니다. [식 2]는 맥락을 왼쪽 2개의 단어로 한정합니다.
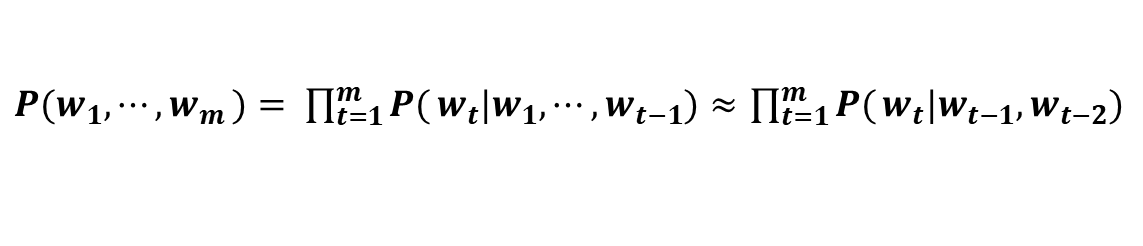
맥락 크기를 특정 값으로 한정하여 나타내면, 맥락 바깥의 정보는 반영되지 않습니다.
그리고 문제점이 더 있습니다. 바로 CBOW 모델에서는 맥락 안의 단어 순서가 무시된다는 점입니다.
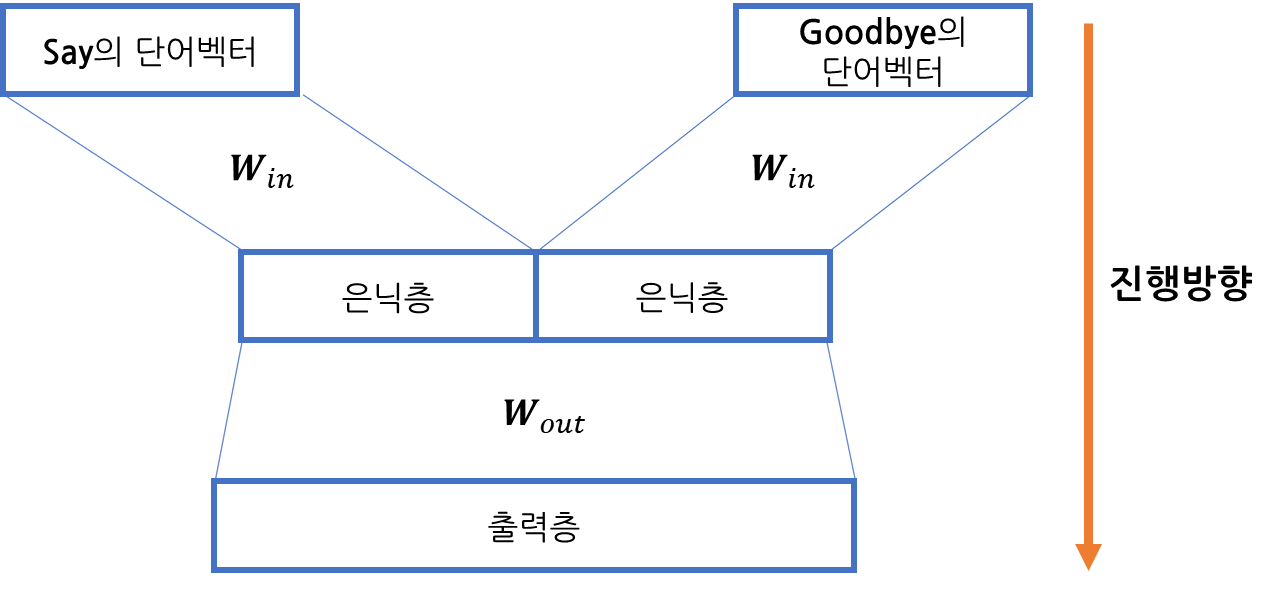
만약 맥락크기가 2일때, 'I say goodbye, you say hello' 문장에서 'you' 예측에는 어떻게 CBOW 모델을 사용할까요? 맥락인 'say, goodbye'를 이용하고 [그림 1]과 같습니다.

[그림 1]에서 모델의 은닉층에서는 'say'와 'goodbye' 단어 벡터들이 더해지므로 맥락의 단어 순서는 무시됩니다.
2) NPLM(Neural Probabilistic Language Model) 에서 제안한 언어모델
맥락의 단어 벡터 순서를 고려하기 위해 [그림 2]와 같이 은닉층에서 단어 벡터를 연결하는 방식이 있습니다. 하지만 이 방식을 취하면, 맥락크기에 비례해서 가중치가 늘어나는 문제점이 생깁니다.
3) RNN의 필요성
RNN은 맥락이 아무리 길어도 그 맥락의 정보를 기억하는 구조로, 순서가 있는 시계열 데이터에도 유연하게 대응할 수 있습니다. 따라서 주어진 문장의 정보를 습득하며 학습한 후, 다음에 올 단어를 예측할 수 있습니다.
'AI' 카테고리의 다른 글
| [LSTM] LSTM을 알아봅시다[밑바닥부터 시작하는 딥러닝2 참고]-I am yumida (0) | 2022.01.16 |
|---|---|
| [RNN] RNN을 알아봅시다[밑바닥부터 시작하는 딥러닝2 참고]-I am yumida (1) | 2022.01.16 |
| 경사하강법에 대하여 알아봅시다.(Do it! 딥러닝 입문 정리) - I am yumida (0) | 2021.08.18 |
| MNIST 데이터를 CNN에 적용하여 분류하기 - I am yumida (0) | 2021.08.12 |
| 안녕 CNN? - I am yumida (0) | 2021.08.11 |