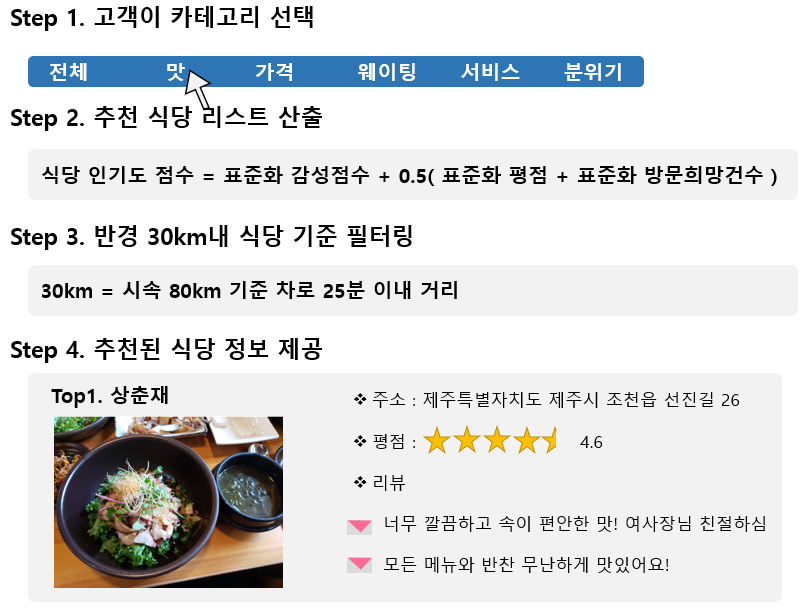
본 게시물은 리뷰기반 식당 추천 리스트를 생성하는 과정으로, 사용한 데이터는 망고플레이트의 제주도 맛집 데이터입니다. 리뷰 기반 감성분석으로 감성점수를 산출하고, [가격, 맛, 서비스, 분위기, 웨이팅] 카테고리별 음식점 추천 리스트를 생성했습니다.
*사용자의 위치를 반영하기 위해 Geocoding을 해서 반경 30Km이내 음식점으로 필터링했습니다.
Geocoding 은 네이버 Api를 이용했으며 R 코딩을 했습니다.
아이디어 구현 과정은 다음과 같습니다.
[목차]
1. 필요한 패키지 설치 및 임포트
2. 망고플레이트 제주도 맛집 링크 수집
3. 망고플레이트 제주도 맛집 식당명, 리뷰, 평점, 주소 등등 수집
4. 맛집 리뷰 형태소분석
5. 맛집 리뷰 단어 빈도 추출
6. Word2Vec과 단어-빈도 행렬을 이용한 리뷰와 카테고리별 연관성 점수 계산
7. 카테고리와 단어의 코사인 유사도 행렬 구하기
8. 단어=문서 행렬 (Term-Document Matrix)
9. 감성분석
10. 생성된 고객 A에 대한 추천리스트
1. 필요한 패키지 설치 및 임포트
!pip3 install beautifulsoup4
import csv
import time
import pandas as pd
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import NoSuchElementException
from selenium import webdriver
import time
import pandas as pd
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
2. 망고플레이트 제주도 맛집 링크 수집
wd = webdriver.Chrome('chromedriver',chrome_options=chrome_options)
wd.get("https://www.mangoplate.com/top_lists/1095_summerguide_jeju")
post_list = []
title_list=[]
for i in range(1,11):
ll = wd.find_element(By.XPATH, "//*[@id='contents_list']/ul/li["+str(i)+"]/div/figure/figcaption/div/span/a").get_attribute('href')
post_list.append(ll)
pageNum = 1
while pageNum < 7:
element=wd.find_element(By.XPATH, '//*[@id="contents_list"]/div/button')
wd.execute_script("arguments[0].click();", element)
time.sleep(1)
for i in range(pageNum*10+1,pageNum*10+11):
try:
ll = wd.find_element(By.XPATH, "//*[@id='contents_list']/ul/li["+str(i)+"]/div/figure/figcaption/div/span/a").get_attribute('href')
post_list.append(ll)
except NoSuchElementException:
print(i)
pageNum += 1
post_infos = pd.DataFrame({'link':post_list})
post_infos.to_csv('data_공모전_link.csv',index=False)
3. 망고플레이트 제주도 맛집 식당명, 리뷰, 평점, 주소 등등 수집
title=[]
review=[]
ID=[]
taste=[]
load=[]
t_1=[] #가고싶다수
t_2=[] #평점
for jj in range(len(post_infos)):
pageNum=0
wd = webdriver.Chrome('chromedriver',chrome_options=chrome_options)
wd.get(post_infos.loc[jj,'link'])
N=wd.find_element(By.XPATH,'/html/body/main/article/div[1]/div[1]/div/section[3]/header/ul/li[1]/button/span').text
if int(N)<=5:
req = wd.page_source
soup=BeautifulSoup(req, 'html.parser')
aa = soup.find_all('p',"RestaurantReviewItem__ReviewText")
bb= soup.find_all('span','RestaurantReviewItem__RatingText')
cc=soup.find_all('span','RestaurantReviewItem__UserNickName')
dd=soup.find('h1','restaurant_name').text
ee=soup.find('div','Restaurant__InfoItemLabel--RoadAddressText').text
ff=soup.find('span','cnt favorite').text
gg=soup.find('strong','rate-point').text
for i in range(len(aa)):
review.append(aa[i].text)
taste.append(bb[i].text)
ID.append(cc[i].text)
title.append(dd)
load.append(ee)
t_1.append(ff)
t_2.append(gg)
if int(N)%5==0:
N_1=int(N)//5-1
else:
N_1=int(N)//5
for _ in range(N_1+1):
element=wd.find_element(By.XPATH, '/html/body/main/article/div[1]/div[1]/div/section[3]/div[2]')
wd.execute_script("arguments[0].click();", element)
time.sleep(3)
req = wd.page_source
soup=BeautifulSoup(req, 'html.parser')
aa = soup.find_all('p',"RestaurantReviewItem__ReviewText")
bb= soup.find_all('span','RestaurantReviewItem__RatingText')
cc=soup.find_all('span','RestaurantReviewItem__UserNickName')
dd=soup.find('h1','restaurant_name').text
ee=soup.find('div','Restaurant__InfoItemLabel--RoadAddressText').text
ff=soup.find('span','cnt favorite').text
gg=soup.find('strong','rate-point').text
for i in range(len(aa)):
review.append(aa[i].text)
taste.append(bb[i].text)
ID.append(cc[i].text)
title.append(dd)
load.append(ee)
t_1.append(ff)
t_2.append(gg)
TOTAL = pd.DataFrame({'review':review, 'ID':ID, 'taste':taste, 'title':title,'load':load, '가고싶다':t_1, '평점':t_2})
for i in range(len(TOTAL['review'])-1):
if TOTAL.loc[i,'review'] in TOTAL.loc[i+1:,'review'].tolist():
print(TOTAL.loc[i,'review'])
TOTAL.to_csv('data_공모전_RAW.csv',index=False)4. 맛집 리뷰 형태소분석
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
TOTAL=pd.read_csv('/content/drive/MyDrive/data_공모전_RAW_1116.csv',sep=',',encoding="cp949")import re
okt=Okt()
ii=[]
data_1=TOTAL.dropna(axis=0)
PP=[]
AA=[]
BB=[]
CC=[]
DD=[]
EE=[]
FF=[]
PP_1=[]
for i in range(len(data_1)):
PP.append(data_1.iloc[i,0]) #review
PP_1.append(data_1.iloc[i,0]) #raw
AA.append(data_1.iloc[i,1]) #ID
BB.append(data_1.iloc[i,2]) #title
CC.append(data_1.iloc[i,3]) #taste
DD.append(data_1.iloc[i,4]) #load
EE.append(data_1.iloc[i,5])
FF.append(data_1.iloc[i,6])
for i in range(len(PP)):
PP[i]=re.sub("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]"," ", PP[i])
PP[i]=okt.morphs(PP[i],norm=True, stem=True)
PP[i]=[x for x in PP[i] if len(x)>1]
PP[i]=' '.join(PP[i])
data_2=pd.DataFrame({'review':PP,'ID':AA,'title':BB,'taste':CC,'raw':PP_1,'load':DD,'가고싶다':EE,'평점':FF})
hangul = re.compile('[ㄱ-ㅣ가-힣]+')
for i in range(len(data_2)):
if len(hangul.findall(data_2.iloc[i,0]))>1:
if len(data_2.iloc[i,0])>1:
ii.append(i)
data_3=data_2.iloc[ii,:]
data_3.to_csv('data_공모전_Noun_1116.csv',index=False)
5. 맛집 리뷰 단어 빈도 추출
##단어 빈도 추출 결과, 카테고리: 가격, 맛, 분위기, 서비스, 웨이팅 카테고리를 생성함
A=data_3.review.to_list()
B=[]
for i in range(len(A)):
B+=A[i].split(' ')words_count={}
for word in B:
if word in words_count:
words_count[word] += 1
else:
words_count[word] = 1
sorted_words = sorted([(k,v) for k,v in words_count.items()], key=lambda word_count: -word_count[1])
print([w[0] for w in sorted_words])
6. Word2Vec과 단어-빈도 행렬을 이용한 리뷰와 카테고리별 연관성 점수 계산
##Word2Vec 카테고리별 코사인 유사도가 높은 단어를 구할 수 있다.
X=[[]]*len(data_3)
for i in range(len(data_3)):
X[i] = data_3.iloc[i,0].split(' ')
from gensim.models import Word2Vec
model_w = Word2Vec(sentences=X,size=500,window=5,min_count=2,workers=4,sg=1)df1=pd.DataFrame(model_w.wv.most_similar('맛있다',topn=20),columns=['단어','맛있다'])
df2=pd.DataFrame(model_w.wv.most_similar('가격',topn=20),columns=['단어','가격'])
df3=pd.DataFrame(model_w.wv.most_similar('웨이팅',topn=20),columns=['단어','웨이팅'])
df4=pd.DataFrame(model_w.wv.most_similar('서비스',topn=20),columns=['단어','서비스'])
df5=pd.DataFrame(model_w.wv.most_similar('분위기',topn=20),columns=['단어','분위기'])
A=list(set(df1.단어.tolist()+df2.단어.tolist()+df3.단어.tolist()+df4.단어.tolist()+df5.단어.tolist()))
A=sorted(A)
pd.DataFrame(A).to_csv('data_공모전_단어리스트_ver4.csv',index=False)
7. 카테고리와 단어의 코사인 유사도 행렬 구하기
##카테고리와 단어의 코사인 유사도 행렬을 구할 수 있다.
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
A=pd.read_csv('/content/drive/MyDrive/data_공모전_단어리스트_ver4_1.csv',sep=',',encoding="cp949")
A=A.iloc[:,0].tolist()
A=sorted(A)
B_맛있다=[]
B_가격=[]
B_웨이팅=[]
B_서비스=[]
B_분위기=[]
for i in range(len(A)):
B_맛있다.append(model_w.wv.similarity('맛있다',A[i]))
B_가격.append(model_w.wv.similarity('가격',A[i]))
B_웨이팅.append(model_w.wv.similarity('웨이팅',A[i]))
B_서비스.append(model_w.wv.similarity('서비스',A[i]))
B_분위기.append(model_w.wv.similarity('분위기',A[i]))
B_total=pd.DataFrame({'맛있다':B_맛있다,'가격':B_가격,'웨이팅':B_웨이팅,'서비스':B_서비스,'분위기':B_분위기}).transpose()
B_total.columns=[A]
B_total[B_total<0.8]=0
B_total.to_csv('data_공모전_단어리스트_ver3_1.csv',index=False)
8. 단어=문서 행렬 (Term-Document Matrix)
from sklearn.feature_extraction.text import CountVectorizer
cv=CountVectorizer()
for i in range(len(X)):
globals()['val_{}'.format(i)]=[]
B=[]
for i in range(len(X)):
for j in X[i]:
if j in A:
globals()['val_{}'.format(i)].append(j)
B.append(i)
C=[]
for j in range(len(X)):
if j not in list(set(B)):
C.append('')
else:
C.append(' '.join(globals()['val_{}'.format(j)]))
DTM_array=cv.fit_transform(C).toarray()
feature_names=cv.get_feature_names()
DTM_DataFrame=pd.DataFrame(DTM_array,columns=feature_names)##카테고리별 리뷰의 연관성을 알 수 있음
import numpy as np
Result=B_total.to_numpy() @ DTM_DataFrame.transpose().to_numpy()
round(pd.DataFrame(Result),4).to_csv('공모전_Relev_결과_1119_2.csv')
B_total.to_csv('공모전_Word2Vec_결과_1119_2.csv')
DTM_DataFrame.to_csv('공모전_DTM_결과_1119_2.csv')
9. 감성분석
##KNU 감성사전에서 팀원과 의논에 음식특화사전을 구축함, lexicon_1_최종사전
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
lexicon=pd.read_csv('/content/drive/MyDrive/lexicon_1_최종사전.csv',sep=',',encoding="cp949")X=[[]]*len(data_3)
for i in range(len(data_3)):
X[i] = data_3.iloc[i,0].split(' ')
##감성점수를 부여하는 과정
A=[0]*len(data_3)
B=[0]*len(data_3)
C=[0]*len(data_3)
for i in range(len(data_3)):
for j in range(len(X[i])):
if X[i][j] in lexicon.word.tolist():
A[i]+=lexicon.polarity.tolist()[lexicon.word.tolist().index(X[i][j])]
B[i]+=1
for i in range(len(C)):
if B[i]!=0:
C[i]=round(int(A[i])/int(B[i]),2)
data_3[['감성점수']]=C
data_3.to_csv('data_공모전_Sent_1121_1.csv',index=False)
10. 생성된 고객A에 대한 추천리스트
추천점수 계산 방식: [(감성점수 * 연관성점수)+0.5(가고싶다수+평점)]
감성점수와 가고싶다수, 평점을 PCA분석한 결과, 감성점수 변수의 영향력이 컸습니다.
따라서 나머지 변수에 가중치를 0.5 곱했습니다.
제주도 맛집 추천리스트는 아래와 같습니다.
| 순위 | 전체 | 맛 | 가격 | 웨이팅 | 서비스 | 분위기 |
| 1 | 밀리우 | 스시호시카이 | 스시호시카이 | 밀리우 | 밀리우 | 밀리우 |
| 2 | 상춘재 | 상춘재 | 상춘재 | 상춘재 | 상춘재 | 상춘재 |
| 3 | 미영이네식당 | 밀리우 | 밀리우 | 스시호시카이 | 스시호시카이 | 스시호시카이 |
| 4 | 중문수두리보말칼국수 | 미영이네식당 | 숙성도 | 미영이네식당 | 미영이네식당 | 미영이네식당 |
| 5 | 숙성도 | 숙성도 | 오드랑베이커리 | 숙성도 | 숙성도 | 숙성도 |
| 6 | 스시호시카이 | 중문수두리보말칼국수 | 닻 | 중문수두리보말칼국수 | 더스푼 | 중문수두리보말칼국수 |
| 7 | 진아떡집 | 더스푼 | 더스푼 | 더스푼 | 어우늘 | 더스푼 |
| 8 | 어우늘 | 우진해장국 | 어우늘 | 천짓골식당 | 중문수두리보말칼국수 | 어우늘 |
| 9 | 국수만찬 | 어우늘 | 천짓골식당 | 우진해장국 | 우진해장국 | 우진해장국 |
| 10 | 더스푼 | 천짓골식당 | 국수만찬 | 진아떡집 | 만선식당 | 진아떡집 |
'대회' 카테고리의 다른 글
| [학위논문] 대응 분석과 토픽 모델링을 이용한 언론사별 계층적 감성분석 - 토픽모델링 CODE (0) | 2022.01.16 |
|---|---|
| [학위논문] 대응 분석과 토픽 모델링을 이용한 언론사별 계층적 감성분석 - 감성분석 CODE (1) | 2022.01.12 |
| Bi-LSTM 기법을 이용한 한국어 뉴스 토픽 분류[CODE] - I am yumida (0) | 2021.09.02 |