제 게시물이 네이버/구글 검색에 뜨지 않는 것을 확인했습니다.. 이런 기운 빠지는 일이.. 손을 좀 봤는데 안 되면 고객 센터에 문의하기로 했습니다.
오늘은 연결 리스트를 활용한 알고리즘 문제를 풀어보겠습니다.
문제는 리트코드 #23. Merge k Sorted Lists 입니다.
https://leetcode.com/problems/merge-k-sorted-lists/
Merge k Sorted Lists - LeetCode
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
leetcode.com
자 시작하겠습니다.
문제
문제: k개의 정렬된 리스트를 1개의 정렬된 리스트로 병합하라.
입력: [
1->4->5,
1->3->4,
2->6
]
출력: 1->1->2->3->4->4->5->6
이 문제에는 연결 리스트, 우선순위 큐 대한 개념이 필요합니다.
연결 리스트에 대한 개념은 https://byumm315.tistory.com/entry/%EB%A6%AC%ED%8A%B8%EC%BD%94%EB%93%9C-23-Merge-k-Sorted-Lists여기 있습니다!
(자료구조) 연결 리스트를 알아봅시다.
제가 요즘 코딩 테스트를 준비하면서 자료 구조도 함께 공부하고 있는데요. 연결 리스트라는 큰 난관에 부딪혀서 어려워하고 있습니다. 따라서 저처럼 연결 리스트를 어려워하시는 분들을 위해
byumm315.tistory.com
우선순위 큐에 대한 개념은 각자 알아봅시다..! 간단해요!
풀이
문제를 풀 때 연결 리스트와 우선순위 큐를 이용합니다. 우선순위 큐를 이용하면 내림차순/오름차순으로 데이터를 추출할 수 있기 때문입니다.
답안 코드
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class Solution:
def mergeKLists(self,lists: List[ListNode]) -> ListNode:
root=result=ListNode(None)
heap=[]
import heapq
for i in range(len(lists)):
if lists[i]:
heapq.heappush(heap, (lists[i].val,i,lists[i]))
while heap:
node=heapq.heappop(heap)
idx=node[1]
result.next=node[2]
result=result.next
if result.next:
heapq.heappush(heap,(result.next.val,idx,result.next))
return root.next
답안 코드 설명
# 연결 리스트 정의하기
class ListNode:
def __init__(self, data=0, next=None):
self.data = data
self.next = next
class Solution:
def mergeKLists(self,lists: List[ListNode]) -> ListNode:
#lists에는 입력값이 들어갑니다.
#전체적으로 리스트 형태이지만 각 원소는 연결 리스트 형태입니다.
# 예) [1->3->4, 2->5, 6->1]
root=head=ListNode(None)
#ListNode(None)은 data와 next를 None으로 둔 연결 리스트입니다.
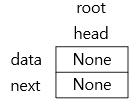
#중요한 개념이 나옵니다. root와 head의 위치를 그림으로 표현하겠습니다.
#[그림 1]과 같이 root 와 head는 같은 위치에 있는 None 인 연결 리스트입니다.
heap=[]
import heapq
#우선순위 큐를 사용하기 위해 모듈을 import 합니다.
for i in range(len(lists)):
#lists의 각 원소는 연결 리스트입니다.
if lists[i]:
heapq.heappush(heap, (lists[i].data,i,lists[i]))
#heappush를 이용해서 (연결리스트의 가장 앞에 있는 데이터값, i, 연결리스트)를 heap에 저장합니다.
#예) lists의 0번째 원소, 1->4->5의 경우 (1, 0, 1->4->5)가 heap에 저장됩니다.
while heap:
#heap이 비어있을 때까지 계속 while문을 돌립니다.
#Step 1. while문의 첫번째 단계 (풀어서 설명하겠습니다.)
node=heapq.heappop(heap)
#heapq.heappop을 이용하면 가장 작은 원소부터 오름차순으로 heap의 원소가 추출됩니다.
#추출된 원소는 heap에서 제거됩니다.
#예) heap=[(1,0,1->4->5), (1,1,1->3->4), (2,2,2->6)]일 때 heappop을 이용하면 (1,0,1->4->5)가 추출됩니다.
#붉은색 위치의 숫자끼리 비교하면 첫번째, 두번째 원소가 가장 작고 그 중에서 파란색 위치의 숫자끼리 비교하면 첫번째 원소가 가장 작기 때문입니다.
idx=node[1]
head.next=node[2]
#head의 뒤쪽 포인터가 node[2] (1->4->5)를 참조하기 때문에 [그림 2]와 같이 변경됩니다.

head=head.next
#head의 뒤쪽 포인터가 1->4->5를 참조하기 때문에 head는 1->4->5의 맨 앞 노드 nodeA로 옮겨집니다.

print(root.next)
print(head.next)
#root.next 는 1->4->5 이고 head.next는 4->5 입니다.
if head.next:
heapq.heappush(heap,(head.next.data,idx,head.next))
print(heap)
#heap은 [(4,0,4->5),(1,1,1->3->4),(2,2,2->6)] 입니다.
return root.next
#Step 2. while문의 두번째 단계를 설명하겠습니다.
node=heapq.heappop(heap)
#heappop을 이용하면 가장 작은 원소부터 오름차순으로 heap의 원소가 추출됩니다.
#추출된 원소는 heap에서 제거됩니다.
#예) heap=[(4,0,4->5), (1,1,1->3->4), (2,2,2->6)] 일 때 heappop을 이용하면 (1,1,1->3->4)가 추출됩니다.
#붉은색 위치의 숫자끼리 비교하면 두번째 원소가 가장 작기 때문입니다.
idx=node[1]
head.next=node[2]
#head의 뒤쪽 포인터가 node[2] (1->3->4)를 참조하기 때문에 [그림 4]와 같이 변경됩니다.

head=head.next
#head의 뒤쪽 포인터가 1->3->4를 참조하기 때문에 head는 1->3->4의 맨 앞 노드 nodeB로 옮겨집니다.

print(root.next)
print(head.next)
#root.next 는 1->1->3->4 이고 head.next는 3->4 입니다.
if head.next:
heapq.heappush(heap,(head.next.data,idx,head.next))
print(heap)
#heap은 [(4,0,4->5),(3,1,3->4),(2,2,2->6)] 입니다.
return root.next
이 과정을 반복하다보면 heap이 빈 값이 됩니다. 이때 root.next를 결과값으로 리턴하면 1->1->2->3->4->4->5->6 이 나옵니다.
감사합니다!!!

'Python' 카테고리의 다른 글
| [프로그래머스] 숫자 문자열과 영단어-I am yumida (0) | 2021.12.12 |
|---|---|
| [프로그래머스] 로또의 최고 순위와 최저 순위-I am yumida (0) | 2021.12.12 |
| [프로그래머스] 메뉴 리뉴얼-I am yumida (0) | 2021.12.04 |
| [프로그래머스] 신규 아이디 추천-I am yumida (0) | 2021.12.04 |
| (자료구조) 연결 리스트를 알아봅시다. - I am yumida (0) | 2021.08.26 |




