오늘은 저의 학위논문 CODE를 올려봅니다.
논문 분야는 텍스트 마이닝으로, 크게 감성분석, 토픽모델링, 대응분석으로 구성됩니다.
대응분석은 SAS로 수행했고 감성분석, 토픽모델링은 Google Colab 환경에서 Python 3.0으로 진행했습니다.
당시 학위논문을 쓰면서 텍스트 마이닝에 흥미를 더욱 가지며 졸업 후, Word Embedding과 Deep Learning으로 공부 영역을 확장했습니다. 현재도, 텍스트 마이닝, NLP 는 가장 관심있는 분야입니다.
그럼, 감성분석 CODE과 토픽모델링 CODE를 올려보도록 하겠습니다.
목차
1. 필요한 패키지 설치
2. 감성 사전 불러오기(감성사전은 분석하는 텍스트가 '뉴스 기사'인 점을 고려해 Bing 감성사전을 번역해 활용했습니다)
3. 감성 사전 품사 추출하기
4. 방역 기사 불러오기
5. 방역 기사 품사 추출하기
6. 기사에 감성을 적용해, 감성 점수 구하기
6-1. 방역 기사 속 품사들과 사전 속 품사를 매치하여 감성 점수를 구하기
6-2. 기사별로 감성 점수를 합치기
1. 필요한 패키지 설치
!apt-get update
!apt-get install g++ openjdk-8-jdk python-dev python3-dev
!pip3 install JPype1-py3
!pip3 install konlpy
!JAVA_HOME="C:\Users\tyumi\Downloads"
2. 감성 사전 불러오기
from google.colab import files
myfile = files.upload()
import io
import pandas as pd
dict_0 = pd.read_excel(io.BytesIO(myfile['Bing 번역 최종.xlsx']))
dict_0.head()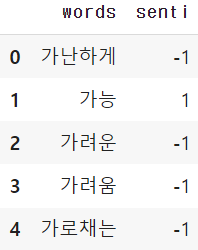
3. 감성 사전 품사 추출하기
from konlpy.tag import * # class
komoran=Komoran()
index=[]
words=[]
score=[]
text_1=[]
for j in range(0,len(dict_0)):
ex_pos=komoran.pos(dict_0.iloc[j,0])
for (text, tclass) in ex_pos : # ('형태소', 'NNG')
if tclass == 'VV' or tclass == 'VA' or tclass == 'NNG' or tclass=='XPN' or tclass == 'NNP'or tclass=='VX' or tclass == 'VCP' or tclass == 'VCN' or tclass == 'MAG' or tclass == 'XR':
index+=[j]
words+=[dict_0.iloc[j,0]]
score+=[dict_0.iloc[j,1]]
text_1.append(text)
dict_1=pd.DataFrame({'Index':index,'Text':text_1,'Words':words,'Score':score})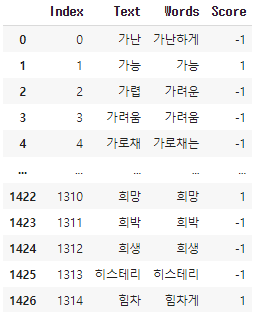
4. 방역 기사 불러오기
from google.colab import files
myfile = files.upload()
import io
import pandas as pd
article_0 = pd.read_excel(io.BytesIO(myfile['방역 기사 추출.xlsx']))
article_0.head()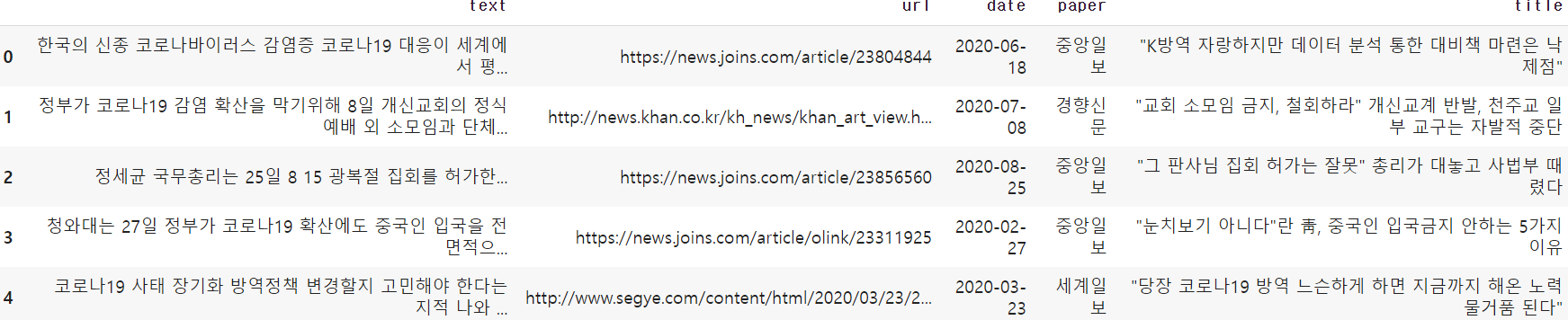
5. 방역 기사 품사 추출하기
import re
index=[]
paper=[]
text_1=[]
text_2=[]
title=[]
for i in range(0,len(article_0)):
article_0.iloc[i,0]=re.sub('\n|\r','',article_0.iloc[i,0]) #문장에서 필요없는 문구 삭제
ex_pos=komoran.pos(article_0.iloc[i,0]) #komoran 품사 태그 적용
for (text, tclass) in ex_pos : # ('형태소', 'NNG')
if tclass == 'VV' or tclass == 'VA' or tclass == 'NNG' or tclass == 'NNP'or tclass=='XPN' or tclass=='VX' or tclass == 'VCP' or tclass == 'VCN' or tclass == 'MAG' or tclass == 'XR':
index+=[i]
paper+=[article_0.iloc[i,3]]
text_1+=[article_0.iloc[i,0]]
text_2.append(text)
title+=[article_0.iloc[i,4]]
article_1=pd.DataFrame({'Index':index,'Text':text_2,'Article':text_1,'Paper':paper,'Title':title})
6. 기사에 감성을 적용해, 감성 점수 구하기
6-1. 방역 기사 속 품사들과 사전 속 품사를 매치하여 감성 점수를 구하기
article_1.loc[:,'Score']=[0]*len(article_1)
dict_list=list(dict_1.loc[:,'Text'])
article_list=list(article_1.loc[:,'Text'])
for i in range(len(dict_list)):
equal_list = list(filter(lambda x: (article_list[x]==dict_list[i]) and (len(article_list[x])>=2), range(len(article_list))))
for j in equal_list:
article_1.loc[j,'Score']=dict_1.loc[i,'Score']
6-2. 기사별로 감성 점수를 합치기
article_0['Score']=article_1['Score'].groupby(article_1['Index']).sum()
article_0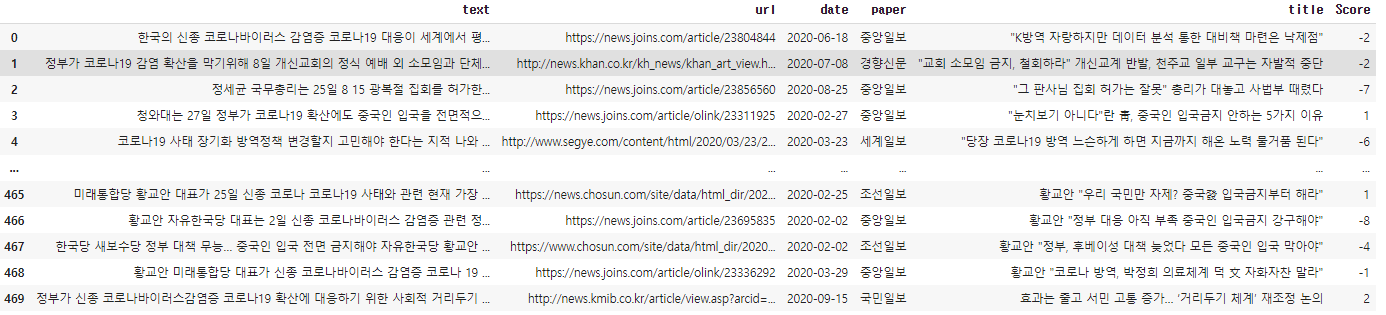
'대회' 카테고리의 다른 글
| [학위논문] 대응 분석과 토픽 모델링을 이용한 언론사별 계층적 감성분석 - 토픽모델링 CODE (0) | 2022.01.16 |
|---|---|
| 리뷰 기반 맛집 추천 시스템 [공모전 결과물]-I am yumida (10) | 2021.11.24 |
| Bi-LSTM 기법을 이용한 한국어 뉴스 토픽 분류[CODE] - I am yumida (0) | 2021.09.02 |