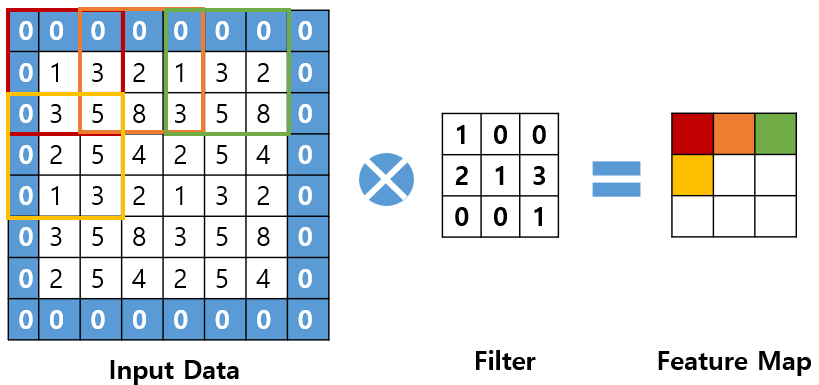
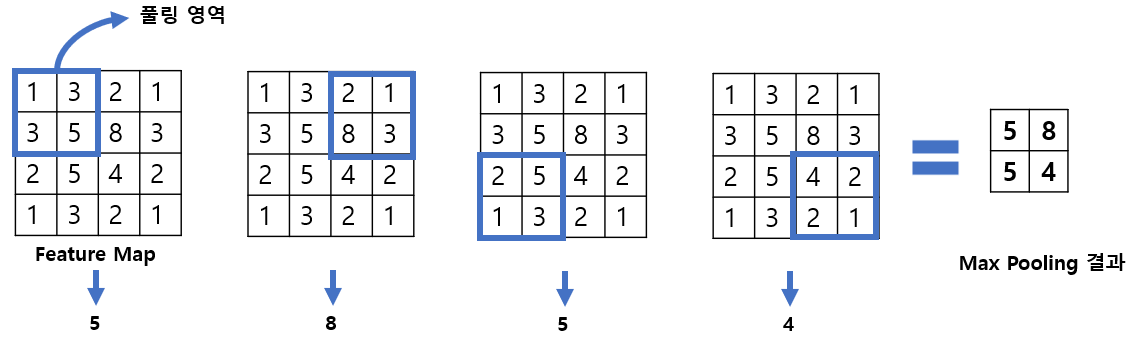
이거 새 게시물을 추가하는 법이 독특하네요.. 한참 찾았습니다..ㅠㅠ
저의 두 번째 게시물은 "MNIST 데이터를 CNN에 적용하여 분류하기"입니다.
MNIST 데이터는 [그림 1]처럼 손으로 쓴 숫자 이미지로 구성되어 있습니다.

저는 이 데이터를 이용해서 실제 숫자를 예측해보겠습니다.
MNIST 데이터는 Kaggle에서 다운로드하였습니다.
링크: https://www.kaggle.com/c/digit-recognizer/data
Digit Recognizer | Kaggle
www.kaggle.com
train, test, sample_submission 데이터로 구성되어 있으며 sample_submission 데이터는 제출용이니 생략합니다.
우선 train 데이터의 관측값은 0-9 중 숫자 하나를 손으로 적은 이미지로, 42000개의 관측값을 갖습니다.
이 이미지는 높이 28, 너비 28 픽셀로 총 784 픽셀입니다. 각 픽셀에는 하나의 픽셀 값이 연결되어 해당 픽셀의 밝기 또는 어두움을 나타내며 숫자가 높을수록 어두워집니다. 이 픽셀 값은 0에서 255(포함) 사이의 정수입니다.
train 데이터의 맨 앞 열은 이미지에 있는 숫자를 나타내고 나머지 784개의 열은 해당 이미지가 갖고 있는 784개의 픽셀을 의미합니다.
따라서 맨 앞 열은 label 변수로 0-9 값을 갖고 나머지 784개의 열은 0에서 255 값을 갖습니다.
test 데이터는 label을 제외한 변수를 갖고 있으며 28000개의 관측값을 갖습니다.
MNIST 데이터 실습은 아래 항목으로 구성됩니다.
1. Colab으로 파일 불러오기
1-1. 구글 마운트 하기
1-2. 파일 불러오기
2. 데이터가 어떻게 생겼을까
3. 데이터를 전처리 하기
3-1. train에서 label은 target, 나머지는 x_train으로 분리합니다.
3-2. 데이터 표준화를 합니다.
3-3. CNN모델 입력 형태로 차원을 변환합니다.
4. 모델 형성하기
5. 전체 코드
그럼 시작하겠습니다.
저는 Google Colaboratory를 이용하기 때문에 Colab 환경에 맞춰서 진행하겠습니다.
1. Colab으로 파일 불러오기
Colab으로 파일을 불러오는 방식은 다양합니다. 저는 Google Mount를 평소에 사용하기 때문에 이걸로 가겠습니다.
1-1. 구글 마운트 하기
위와 같이 코드를 치면 authorization code를 입력하는 란이 나옵니다. 위의 파란색 url에 접속하면 code를 받을 수 있습니다. code를 복사하여 입력란에 붙여 넣고 Enter를 치면 됩니다.
1-2. 파일 불러오기

위와 같이 입력하면 csv파일을 불러올 수 있습니다.
2. 데이터가 어떻게 생겼을까
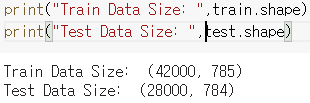
train, test 데이터의 size를 알 수 있습니다.
이번에는 train 데이터 42000개 중 0부터 3번째 데이터를 이미지로 직접 나타내 보겠습니다.
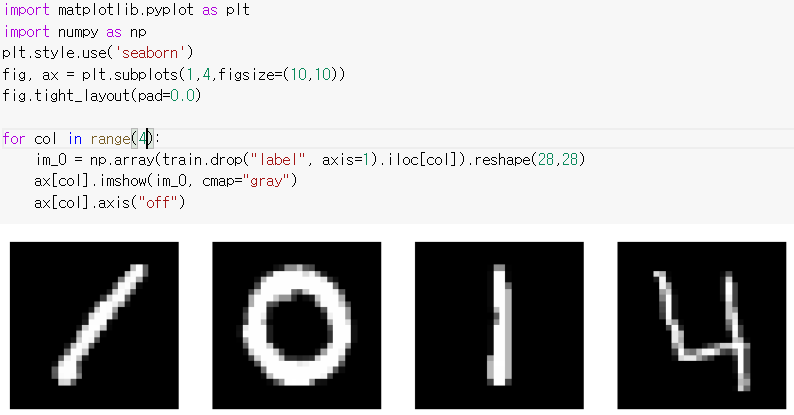
3. 데이터를 전처리하기
3-1. train에서 label은 target, 나머지는 x_train으로 분리합니다.

3-2. 데이터 표준화를 합니다.
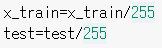
픽셀이 0~255의 정수 값을 갖기 때문에 255로 나눠서 표준화하였습니다.
3-3. CNN모델 입력 형태로 차원을 변환합니다.

4. 모델 형성하기
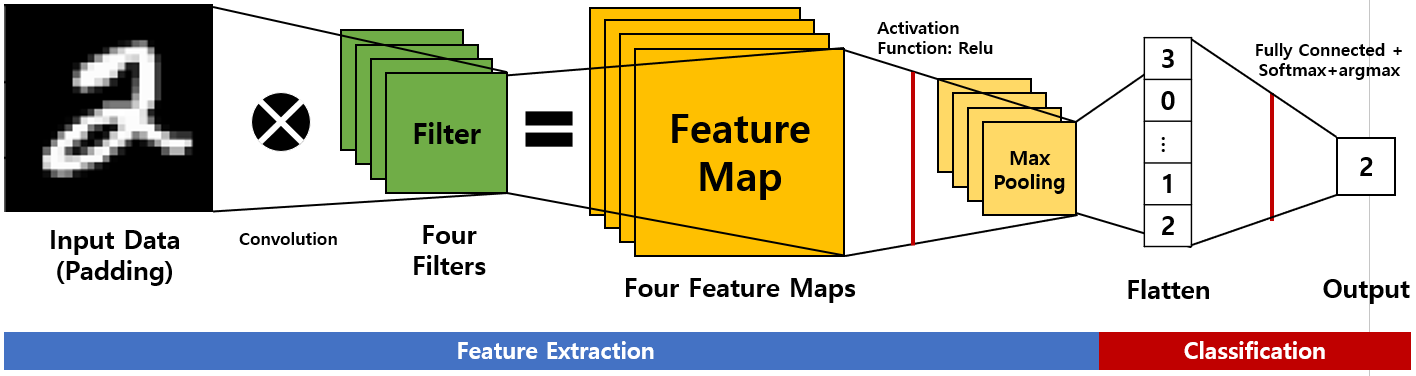
[그림 2]에서는 이번 실습 때 사용하는 CNN 모델 프로세스를 자세히 보여줍니다.
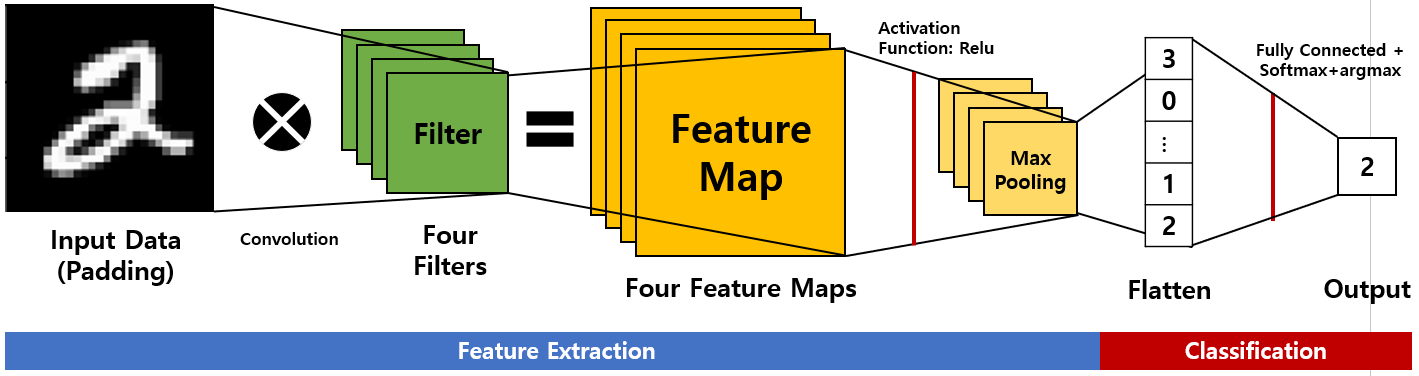
직접 코드로 구현해봅시다.
아래의 코드를 봅시다.
우선 모델 형성에 필요한 패키지를 설치하고요.

모델 층을 쌓는 코드에는 중간중간 설명을 적겠습니다. (하단에 정리한 코드 올려놓았습니다.)
model=keras.Sequential([
Sequential은 신경망 층을 쌓을 때 사용합니다.
앞으로 나오는 각 코드를 우리는 하나의 계층이라고 하겠습니다.
keras.layers.Conv2D(32, kernel_size=(3,3), input_shape=(28,28,1), padding='SAME', activation=tf.nn.relu)
첫 번째 층은 컨볼루션층입니다
맨 앞(32): Kernel(Filter) 수입니다.
kerel_size: Kernel의 크기를 지정합니다.
input_shape: 샘플 수를 제외한 입력 형태를 정의합니다. (행, 열, 채널 수)로 정의합니다.
(채널은 색상(R, G, B)을 의미하고 사용하는 데이터는 흑백 이미지이기 때문에 채널 수가 1입니다.)
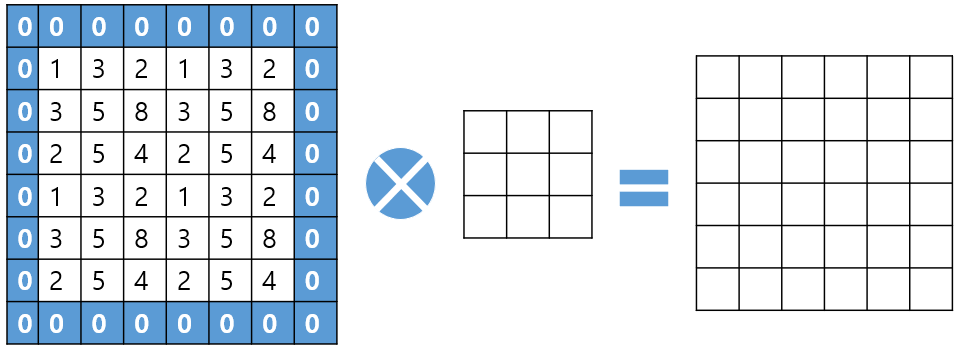
Padding: padding이 'SAME'이면 출력 데이터 사이즈와 입력 데이터 사이즈가 동일합니다.
Activation: 활성화 함수를 설정합니다.
keras.layers.MaxPool2D(pool_size=(2,2), strides=(2,2), padding='SAME')
다음은 MaxPooling 계층입니다.
pool_size: Pooling 영역의 크기입니다.
strides: Pooling 영역이 이동하는 간격을 의미합니다.
keras.layers.Conv2D(64, kernel_size=(3,3), padding='SAME', activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size=(2,2), strides=(2,2), padding='SAME')
위의 코드를 반복합니다. (본 실습에서는 컨볼루션층을 두 번 거칩니다.)
keras.layers.Flatten()
앞에서는 Image data의 Feature Maps를 추출했습니다. 이번에는 실제 숫자로 분류하는 작업을 해보겠습니다.
Flatten 계층을 이용하여 3차원의 데이터를 1차원으로 변환합니다.
keras.layers.Dense(1024, activation='relu')
이후 완전 연결 계층 (Dense)를 적용합니다.
units: 1024는 완전 연결 계층을 거친 후 나오는 출력 데이터의 수를 의미합니다.
keras.layers.Dense(10, activation='softmax')
마지막 완전 연결 계층은 units이 10이고 활성화 함수가 Softmax 입니다.
0에서 9 사이의 숫자를 예측하기 때문에 10개의 클래스로 분리됩니다.
따라서 이 계층을 지난 후 나오는 출력 데이터의 수가 10이 되어야 하구요.
활성화 함수로 Softmax를 쓰면 각 클래스로 예측될 확률을 알 수 있습니다.
예를 들면, 1로 분류될 확률이 0.1, 2로 분류될 확률이 0.3 등 (확률의 전체 합은 1이겠죠?!)
keras.layers.Dropout(0.25)
마지막으로 Dropout 계층입니다.
Dropout 계층은 과적합(over-fitting)을 막기 위한 방법으로 신경망이 학습 중일 때, 무작위로 신경망을 빼서 모델 학습을 방해함으로써, 과적합을 방지합니다.
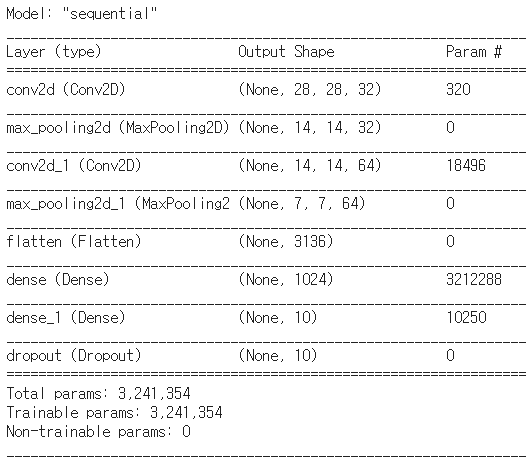
[그림 3]는 형성한 모델의 각 계층을 지나면서 출력되는 Output의 차원을 보여줍니다.
(Output Shape에서 확인 가능합니다.)
5. 전체 코드
다음과 같습니다.
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
test=pd.read_csv('/content/drive/MyDrive/test.csv')
train=pd.read_csv('/content/drive/MyDrive/train.csv')
sample_sub=pd.read_csv('/content/drive/MyDrive/sample_submission.csv')
print("Train Data Size: ", train.shape)
print("Test Data Size: ", test.shape)
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('seaborn')
fig, ax = plt.subplots(1,4, figsize=(10,10))
fig.tight_layout(pad=0.0)
for col in range(4):
im_0 = np.array(train.drop("label", axis=1). iloc [col]). reshape(28,28)
ax [col]. imshow(im_0, cmap="gray")
ax [col]. axis("off")
target = train ['label']
x_train = train.drop('label', axis = 1)
x_train=x_train/255
test=test/255
x_train = np.array(x_train). reshape((-1,28,28,1))
x_train.shape
test = np.array(test). reshape((-1,28,28,1))
test.shape
from tensor flow.keras.utils import to_categorical
target = to_categorical(target, num_classes = 10)
target.shape
import tensorflow as tf
from tensorflow import keras
model=keras.Sequential([
keras.layers.Conv2D(32, kernel_size=(3,3), input_shape=(28,28,1), padding='SAME', activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size=(2,2), strides=(2,2), padding='SAME'),
keras.layers.Conv2D(64, kernel_size=(3,3), padding='SAME', activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size=(2,2), strides=(2,2), padding='SAME'),
keras.layers.Flatten(),
keras.layers.Dense(1024, activation='relu'),
keras.layers.Dense(10, activation='softmax'),
keras.layers.Dropout(0.25)])
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary() #각 계층별 출력 데이터의 차원을 확인하실 수 있습니다.
model.fit(x_train, target, epochs=5) #모델 학습
pred=np.argmax(model.predict(x_train), axis=-1) #분류한 결과를 확인하실 수 있습니다.
출처 1: https://www.kaggle.com/mhmdsyed/digital-recognizer-simple-cnn-model
Digital Handwriting Recognizer ✍️ |
Explore and run machine learning code with Kaggle Notebooks | Using data from Digit Recognizer
www.kaggle.com
출처 2: https://dsbook.tistory.com/71?category=780563
합성곱 신경망, Convolutional Neural Network (CNN)
완전 연결 계층, Fully connected layer (JY) Keras 사용해보기 1. What is keras? 케라스(Keras)는 텐서플로우 라이버러리 중 하나로, 딥러닝 모델 설계와 훈련을 위한 고수준 API이다. 사용자 친화적이고 모델의
dsbook.tistory.com
제가 블로그가 처음이라서 출처를 어떻게 남기는지, 직접 말씀드려야 하는지 잘 모르겠습니다..
만약 이 방법이 틀렸음 알려주신다면 감사드리겠습니다!
피드백, 질문 언제든지 환영입니다!!
다음은 RNN 이론을 올리겠습니다!

'AI' 카테고리의 다른 글
| [LSTM] LSTM을 알아봅시다[밑바닥부터 시작하는 딥러닝2 참고]-I am yumida (0) | 2022.01.16 |
|---|---|
| [RNN] RNN을 알아봅시다[밑바닥부터 시작하는 딥러닝2 참고]-I am yumida (1) | 2022.01.16 |
| [RNN] RNN에 들어가기 전에..(밑바닥부터 시작하는 딥러닝2) - I am yumida (0) | 2021.12.30 |
| 경사하강법에 대하여 알아봅시다.(Do it! 딥러닝 입문 정리) - I am yumida (0) | 2021.08.18 |
| 안녕 CNN? - I am yumida (0) | 2021.08.11 |