CNN은 Convolutional Neural Networks의 줄임말로 알다가도 모르는 기법이다.
그래서 이론을 확실히 하기 위해서 CNN 개념 및 원리를 올려본다.
최대한 알기 쉽게 설명하도록 하겠다. 피드백은 언제나 환영이다. 댓글도 Welcome이다.
이 글의 항목은 아래와 같다.
1. CNN의 NN, Neural Networks(신경망) 이란 무엇인가?
2. CNN이란 무엇인가?
1. CNN의 NN, Neural Networks(신경망) 이란 무엇인가?
[그림 1]은 신경망의 원리를 잘 보여주는 예시로, 이 예시를 바탕으로 신경망을 설명하겠다.
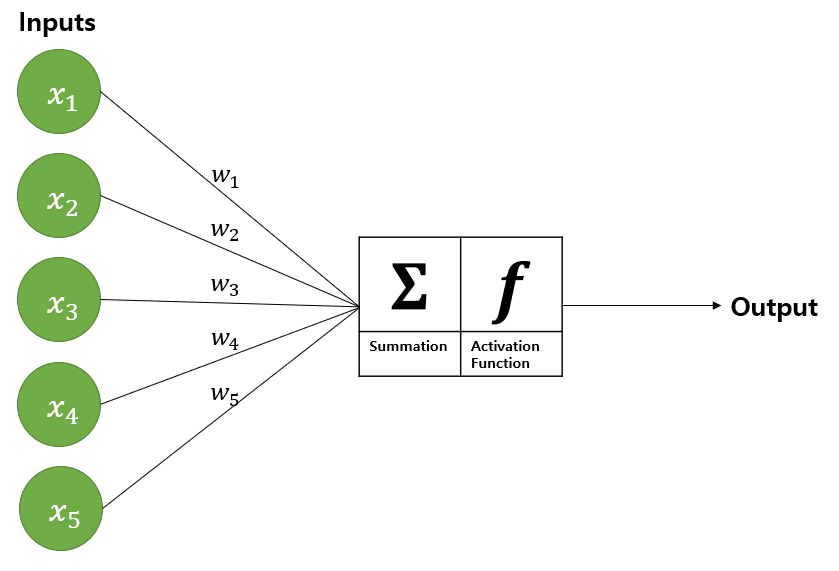
Step.1 Inputs은 데이터를 넣는 곳으로 만약 데이터 [1,2,3,4,5]를 신경망에 넣고 싶으면 Inputs에 [1,2,3,4,5]를 할당하면 된다. (x1=1, x2=2,..., x5=5)
Step.2 w1부터 w5는 가중치이다. 가중치와 Inputs의 각 원소를 곱한다.
(x1*w1, x2*w2,..., x5*w5)
Step.3 Step.2에서 구한 가중치와 원소의 곱을 모두 합한다.
(x1*w1+x2*w2+...+x5*w5)
Step.4 Step.3에 활성화 함수를 씌워서 출력한다. 활성화 함수는 Activation Function이며, 시그모이드, 렐루, 소프트 맥스 등이 사용된다.
2. CNN이란 무엇인가?
2번 섹션은 세 개의 항목으로 나눴다.
2-1. 합성곱(Convolution)을 알아보자
2-2. CNN의 프로세스를 통째로 알아보자
2-3. CNN의 프로세스를 세부적으로 알아보자
1번 섹션에서는 1차원 데이터를 신경망에 적용했다. 그렇다면 이미지와 같은 2차원 데이터는 어떻게 신경망에 적용할까?
정답은 지금부터 알아볼 CNN이다.
CNN은 Convolutional Neural Networks의 약자로, 핵심은 신경망에서 사용된 연산을 합성곱으로 교체한 것이다.
새로운 개념이 나왔다.
합성곱이 무엇일까? 2-1 섹션에서 차근차근 알아보자.
2-1. 합성곱(Convolution)을 알아보자
합성곱은 곱셈과 덧셈으로 이루어진 연산이다.
[그림 2]에서 행렬 A와 행렬 B를 합성곱 하여 행렬 C를 만들었다.
행렬 A와 행렬 B의 차원이 다른데 어떻게 곱셈이 가능할까?
정답: 행렬 A 위에서 행렬 B를 이동시키며 겹치는 원소들끼리 곱하고 더한다.
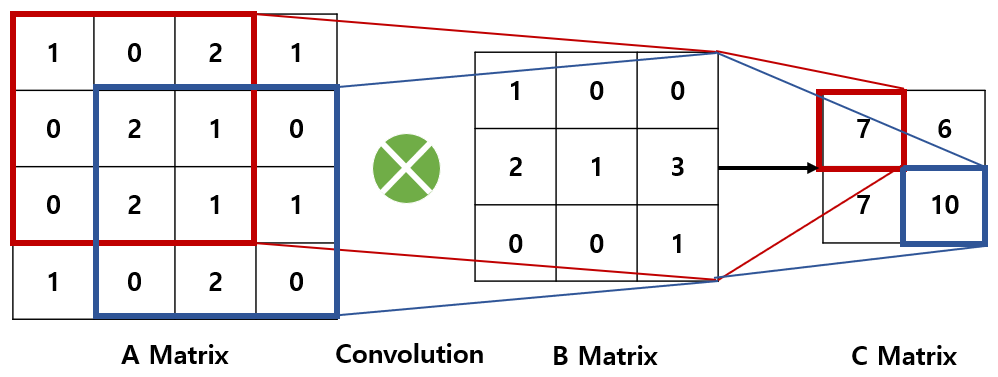
[그림 2]를 단계별로 설명해보겠다.
Step 0. 행렬 A 위에 행렬 B를 올려놓는다.([그림 2]의 빨간색 네모 위에 행렬 B를 올려놓는다)
Step 1. 행렬 A의 빨간색 네모와 행렬 B의 각 원소를 곱하고 모두 더하면 행렬 C의 첫 번째 원소 7이 나온다.
(실제 계산: 1*1+0*0+2*0+0*2+2*1+1*3+0*0+2*0+1*1=7)
Step 2. 이제 행렬 B를 오른쪽으로 이동시킨다.
행렬 A와 겹치는 부분의 각 원소를 곱하고 모두 더한다. 행렬 C의 두 번째 원소 6이 나온다.
Step 3. 이번에는 행렬 B를 대각선 아래로 이동시킨다.
행렬 A와 겹치는 부분의 각 원소를 곱하고 모두 더한다. 행렬 C의 세 번째 원소 7이 나온다.
Step 4. 마지막으로 행렬 B를 왼쪽으로 이동시킨다.
[그림 2]에서 행렬 A의 파란색 네모와 행렬 B의 각 원소를 곱하고 모두 더하면 행렬 C의 네 번째 원소 10이 나온다.
Step 5. 이렇게 행렬 B가 행렬 A 위를 다 돌고 나면 행렬 C가 완성된다. 이 과정에서 사용된 연산이 바로 합성곱이다.
2-2. CNN의 프로세스를 통째로 알아보자
[그림 3]은 CNN의 원리로, 컴퓨터에서 CNN을 통해 이미지를 숫자 2로 분류하는 과정을 보여준다.
[그림 3]으로 CNN의 프로세스를 설명해보겠다.
우선 Input Data에 들어간 이미지 데이터가 가진 특징들을 추출하는 Feature Extraction 작업을 거친다.
이후 자동차 이미지면 자동차, 숫자 2 이미지이면 숫자 2 등으로 분류하는 Classification 작업을 거친다.
[그림 3]은 이미지를 0에서 9 사이의 숫자 중 하나로 분류하는 과정이다.
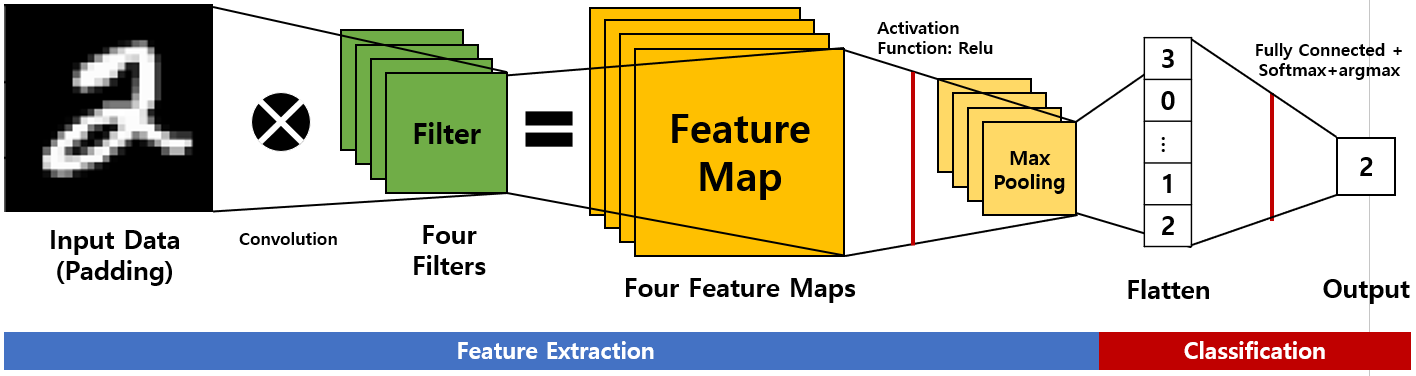
좀 더 알아보자.
Step 1. Image Data에 Padding을 하여 Input Data에 넣는다. 여기서 Padding은 '덧댄다'는 의미로, 합성곱 작업을 거치면 결과의 차원이 줄어드는 문제를 방지하기 위하여 Input Data의 모서리에 0이나 다른 숫자를 덧대는 작업을 한다.
(Padding 은 2-3 섹션에서 자세히 알아보자)
Step 2. 특성 맵(Feature map)을 추출하기 위하여 Input Data와 Filter를 합성곱(Convolution) 한 후 Relu라는 활성화 함수를 씌운다. [그림 3]에는 네 개의 Filter가 있다. Input Data와 네 개의 Filter를 각각 합성곱 한 후 활성화 함수를 적용하면 네 개의 특성 맵(Feature Maps)이 나온다.
Step 3. Feature Maps의 차원의 복잡성을 줄이면서 유의미한 정보는 유지하기 위해 Max Pooling을 이용한다.
(Pooling은 2-3 섹션에서 자세히 알아보자)
Step 4. Flatten을 통하여 3차원의 Feature Maps(Step 3의 결과)를 1차원의 형태로 변형시킨다.
Step 5. Step 4의 결과를 완전 연결 신경망에 적용한 후 0에서 9 사이의 숫자일 확률을 구하기 위해 Softmax 함수를 적용한다. CNN에 입력한 이미지 데이터가 0일 확률부터 9일 확률까지 알 수 있다.
Step 6. Step5의 결과에 최대의 확률을 가진 값을 구하는 argmax함수를 적용한다. [그림 3]의 Output에서 2로 분류된 것을 알 수 있다.
2-3. CNN의 프로세스를 세부적으로 알아보자
1) Padding
CNN에서 이미지의 특징을 추출하기 위하여 Filter와 합성곱 하는 과정을 거친다.
이후 차원이 축소되면서 정보가 손실되는 경향을 보이는데, 차원이 줄어드는 것을 예방하기 위해 사전 작업으로 이미지 데이터에 Padding(덧대기)를 한다.
[그림 4]는 Padding 예시이다.
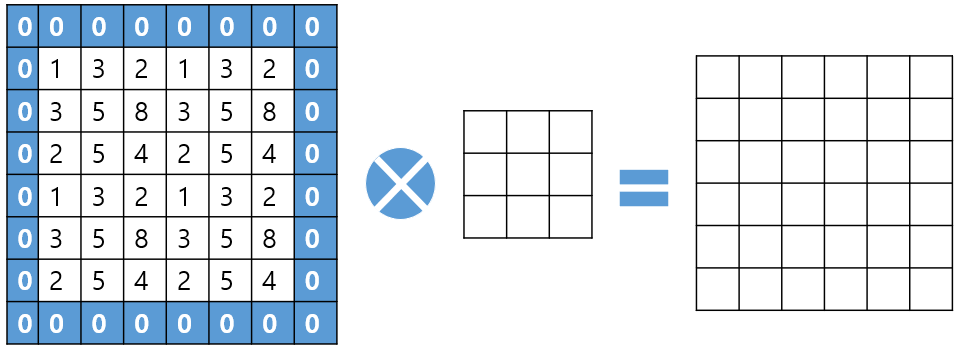
Padding은 두 가지 방법이 있다. 하나는 [그림 4]와 같이 데이터의 테두리에 0을 덧대는 방법, 다른 하나는 데이터의 테두리 값을 복사하여 덧대는 방법이 있다.
[그림 4]처럼 테두리에 0을 덧대면 합성곱 이후에도 차원이 유지됨을 알 수 있다.
2) Filters
CNN에서 Input Data와 Filter를 합성곱 한 후 Input Data의 특성 맵(Feature Map)이 추출된다.
Filter가 어떤 값을 가지느냐에 따라서 추출되는 특성 맵이 달라지고 Input Data를 얼마큼의 간격으로 이동하느냐에 따라서도 달라지는데 이 간격을 'Stride'라고 한다. 또한 n개의 Filter를 이용하면 n개의 특성 맵이 추출된다.
참고로 CNN에서 Filter와 Kernel은 같은 의미이다.
이해를 돕기 위해 [그림 5]를 보며 설명하겠다.
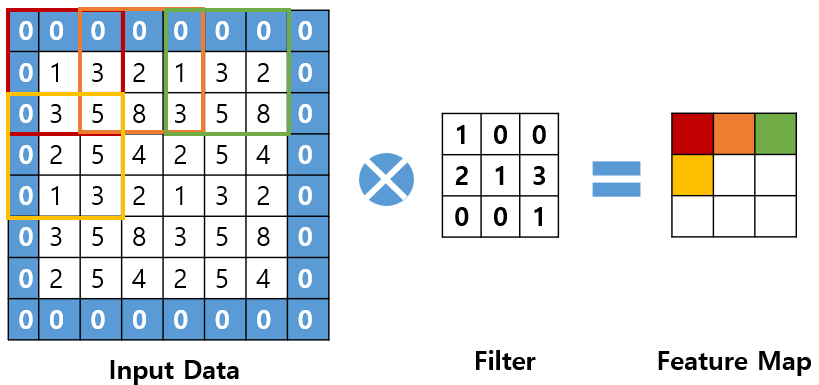
[그림 5]는 Padding을 씌운 Input Data와 Filter의 합성곱을 나타낸다. 이때 Filter의 수는 한 개라서 하나의 특성 맵이 추출되고 Filter가 Input Data 위를 이동하는 간격은 2이다.
[그림 5]에서 Input Data의 빨간색 네모와 Filter와 연산하여 Feature Map의 빨간 부분이 계산되고 2칸을 이동한 Input Data의 주황색 네모와 Filter와 연산하여 Feature Map의 주황색 부분이 계산된다. 이런 식으로 반복하면 하나의 Feature Map이 완성된다.
3) Pooling
Pooling은 특성 맵을 스캔 하여 최댓값을 고르거나 평균값을 계산하는 것을 의미한다. 보통 연구자들은 최댓값을 고르는 Pooling 방식(Max Pooling)을 선호한다. 그 이유는 Input Data에서 각 Filter가 찾고자 하는 부분은 Feature Map의 가장 큰 값으로 활성화되는데 Max Pooling 방식은 Feature Map의 차원은 줄이면서 유의미한 정보이자, 가장 큰 특징은 유지시키는 성질이 있기 때문이다.
[그림 6]은 Max Pooling의 예시이다.
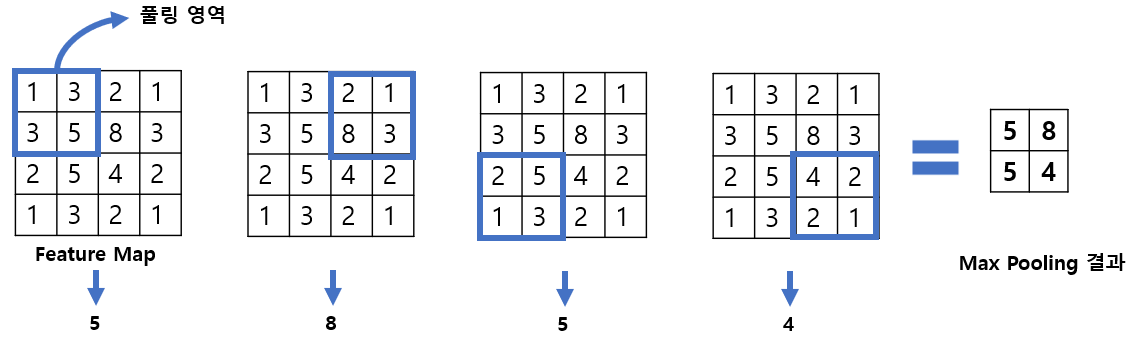
하나의 Feature Map이 있으면 이 위를 풀링 영역이 지나가면서 최댓값을 가져온다. 풀링 영역은 사용자가 지정할 수 있으며 보통 2x2를 크기로 지정한다. 그리고 이동 간격(Stride)은 풀링 영역의 한 모서리 크기로 지정한다.
[그림 6]에서 첫 번째 풀링 영역에서 최댓값 5를 뽑아내고 두 칸 이동한 두 번째 풀링 영역에서 최댓값 8을, 왼쪽 대각선 아래로 이동한 세 번째 풀링 영역에서 최댓값 5를, 두 칸 이동한 네 번째 풀링 영역에서 최댓값 4를 뽑아낸다.
다음 게시물에서는 MNIST DATA가 CNN에서 어떻게 굴러가는지 Python 실습을 통해 알아보자
'AI' 카테고리의 다른 글
| [LSTM] LSTM을 알아봅시다[밑바닥부터 시작하는 딥러닝2 참고]-I am yumida (0) | 2022.01.16 |
|---|---|
| [RNN] RNN을 알아봅시다[밑바닥부터 시작하는 딥러닝2 참고]-I am yumida (1) | 2022.01.16 |
| [RNN] RNN에 들어가기 전에..(밑바닥부터 시작하는 딥러닝2) - I am yumida (0) | 2021.12.30 |
| 경사하강법에 대하여 알아봅시다.(Do it! 딥러닝 입문 정리) - I am yumida (0) | 2021.08.18 |
| MNIST 데이터를 CNN에 적용하여 분류하기 - I am yumida (0) | 2021.08.12 |