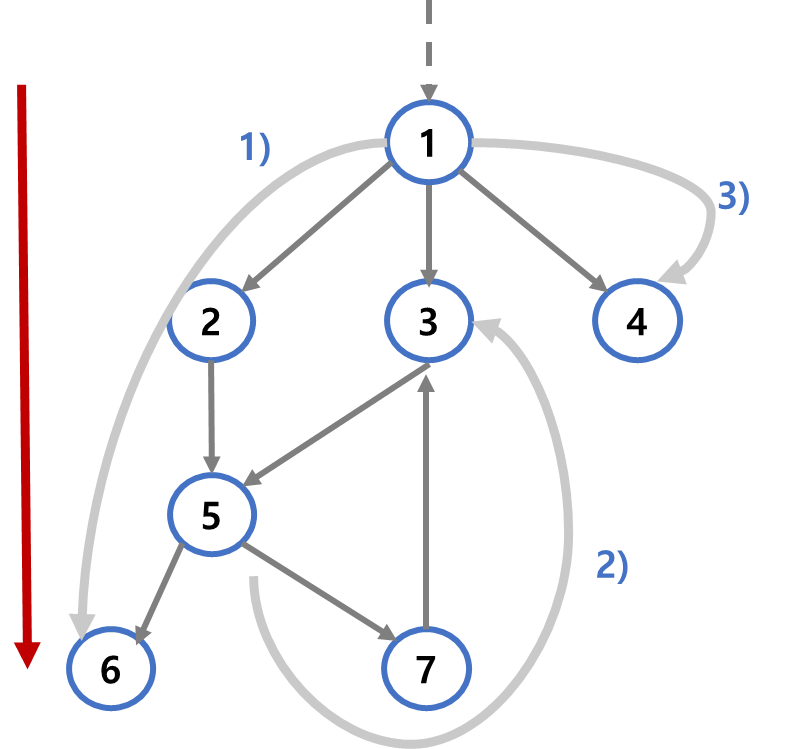
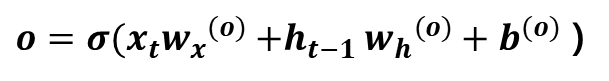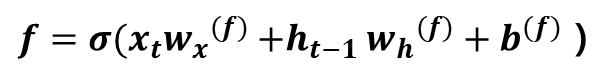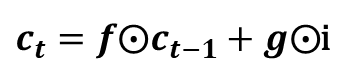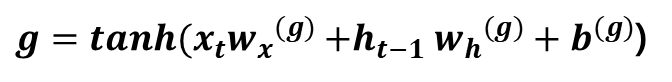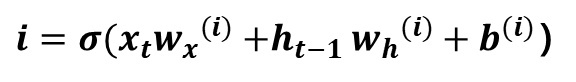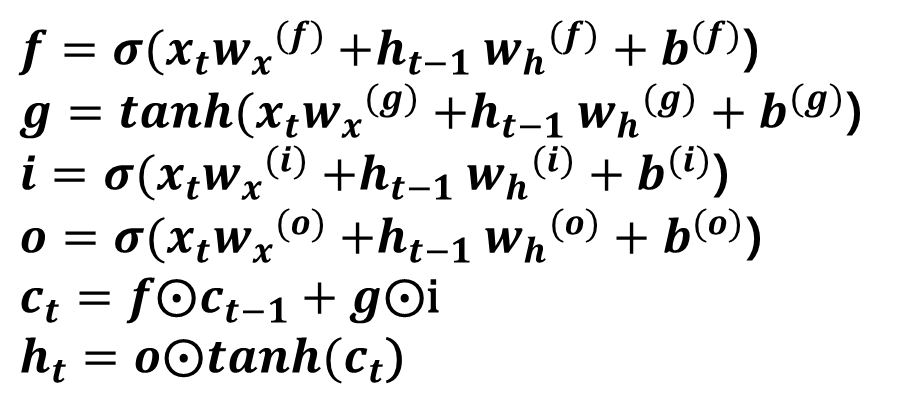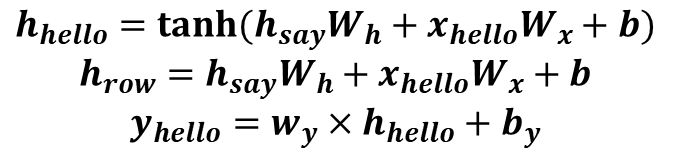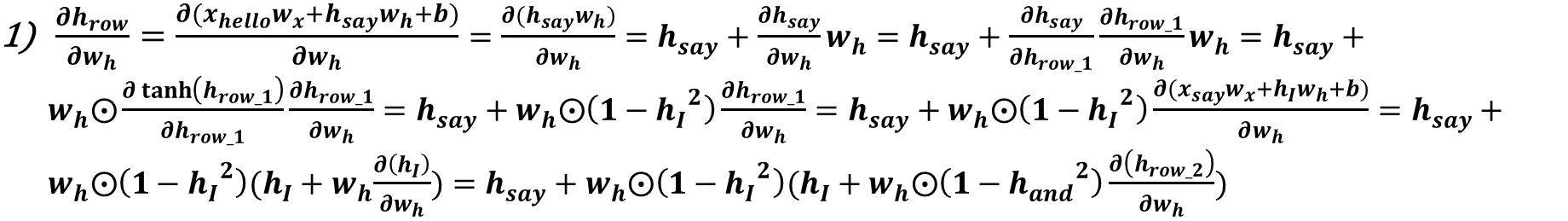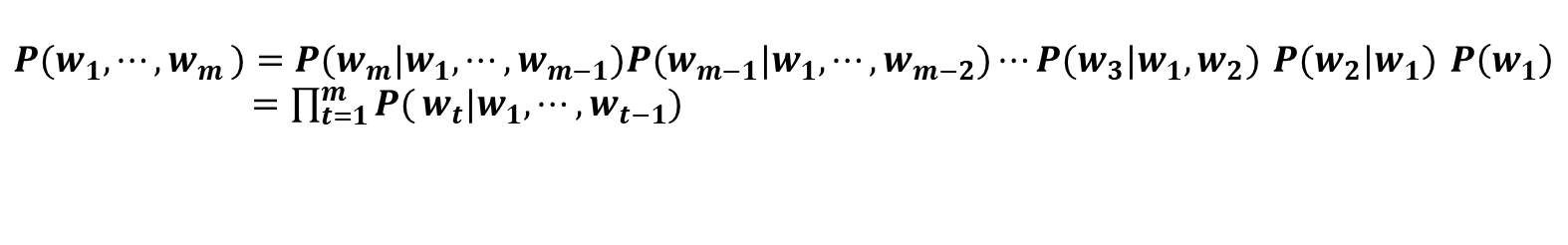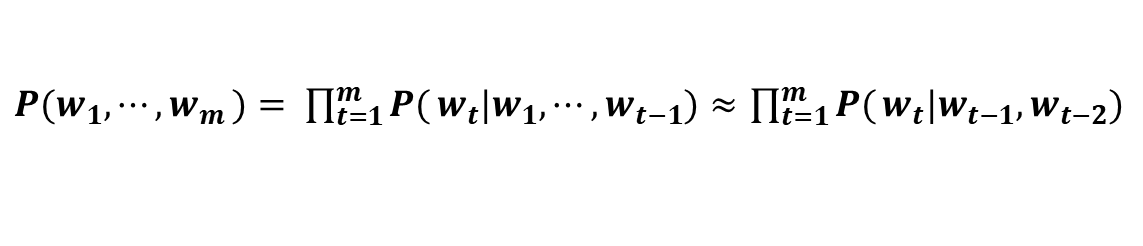2) 시작점, 끝점을 제외한 문자열 역시 팰린드롬입니다. ('bacab'의 경우 양끝을 제외한 'aca'역시 팰린드롬입니다)
아래는 문제에 대한 풀이입니다.
1. Two Pointer를 이용한 방식
s='abacaba'
result={}
answer=[]
for i in range(len(s)):
for j in range(0,2):
left,right=i,i+j
while left>=0 and right<len(s) and s[left]==s[right]:
left-=1
right+=1
if s[left+1:right] not in result.keys():
result[s[left+1:right]]=1
else:
result[s[left+1:right]]+=1
for i in result:
answer.append(len(i)*result[i])
print(max(answer))
3) for문을 이용해 result에서 키(key)의 길이와 해당하는 값(value)을 곱해 answer 리스트에 저장했습니다.
이후 가장 큰 값을 출력했습니다. answer 리스트는 아래와 같습니다.
[4, 2, 6, 1, 3, 5, 7]
4) 정답은 7입니다.
2. DP(다이나믹 프로그래밍)를 이용한 방식
s='abacaba'
n=len(s)
dp = [[0] * n for _ in range(n)]
answer=[]
answer_1=[]
for num_len in range(n):
for start in range(n - num_len):
end = start + num_len
# 시작점과 끝점이 같다면 글자수가 1개이므로 무조건 팰린드롬
if start == end:
dp[start][end] =1
answer.append(s[start:end+1])
# 시작점의 글자와 끝점의 글자가 같다면
elif s[start] == s[end]:
# 두 글자짜리 문자열이라면 무조건 팰린드롬
if start + 1 == end:
dp[start][end] = 1
answer.append(s[start:end+1])
# 가운데 문자열이 팰린드롬이라면 팰린드롬
elif dp[start+1][end-1] == 1:
dp[start][end] = 1
answer.append(s[start:end+1])
from collections import Counter
for i in Counter(answer):
answer_1.append(len(i)*Counter(answer)[i])
print(max(answer_1))
1) 문자열 길이의 행과 열을 가진 DP Table dp를 만듭니다.
2) 이중for문을 통해 시작점과 끝점사이 길이가 0일때부터 n일때까지 범위를 지정합니다.
따라서 길이가 0인 부분문자열부터 n인 부분문자열까지 확장하는 방식으로 팰린드롬을 찾습니다.
이것은 크기가 작은 부분문자열부터 팰린드롬 유무를 확인하고 문자열의 크기를 조금씩 크게 만들면서 팰린드롬 유무를 확인한다는 점에서 DP의 Bottom - Up 방식과 유사합니다.
DP에서 문제가 팰린드롬 유무를 찾기라면 작은 문제를 풀면서 큰 문제의 해답을 찾는다는 점에서 유사합니다.
2-1) 예를 들면, 길이가 7인 'abacaba'가 팰린드롬인지 알려면, 양 끝점을 봅니다.
양 끝점이 'a'로 같기 때문에, 팰린드롬일 가능성이 있습니다.
이제, 양 끝점을 제외한 나머지 문자열'bacab'가 팰린드롬인지 알아야 됩니다.
그런데, 우리는 이미 앞에서 길이가 5인 부분 문자열에 있는 팰린드롬들을 구했습니다.
따라서 'bacab'가 팰린드롬임을 알 수 있습니다.
가운데에 있는 'bacab'가 팰린드롬이기 때문에, 'abacaba' 역시 팰린드롬입니다.
3) 문자열 안에 있는 부분문자열이 팰린드롬인 경우, dp[시작점][끝점]에 1을 부여합니다.
아래의 그림의 0번째 줄을 예로 들면, 0번째 원소와 2번째 원소가 1입니다. 즉, 시작위치가 0, 끝위치가 2인 원소 'aba'가 팰린드롬임을 의미합니다.
4) 문자열 안에 있는 부분문자열이 팰린드롬인 경우, 해당 문자열을 answer 리스트에 저장합니다.
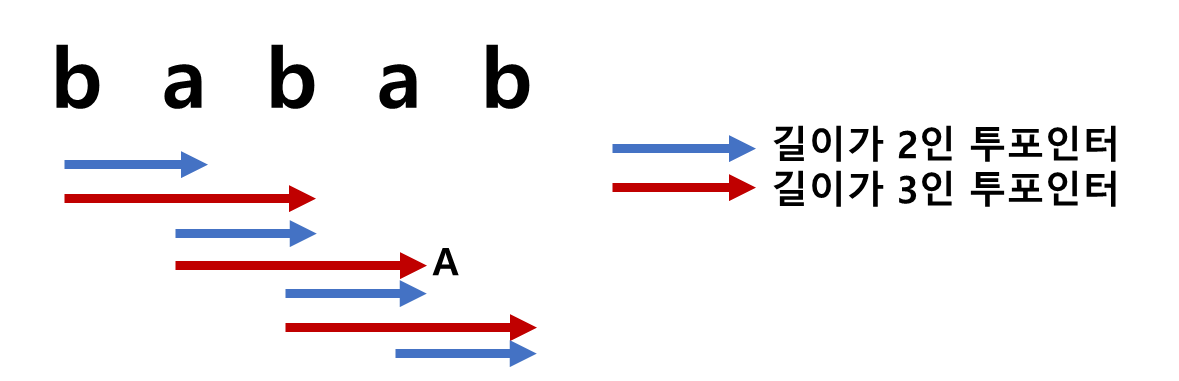
저는 투포인터가 중앙을 중심으로 확장하는 형태로 풀이했습니다. 'babab'를 통해 가장 긴 팰린드롭을 구하는 풀이를 설명드리겠습니다.우선 [그림1]과 같이 길이가 2, 3인 두 개의 투포인터를 'babab'에 배치합니다.
[그림 1]
여기서 A와 같이 투포인터가 가리키는 시작점과 끝점의 원소가 같다면, 팰린드롭을 의미합니다. [그림 1]에서 'bab', 'aba' 가 있습니다.
하지만 'aba' (A)의 경우, 다른 팰린드롭과 다르게 양옆에 문자열이 있어서 양옆으로 투포인터를 확장할 수 있습니다. 확장하면 'babab'가 됩니다. 이 역시 양끝이 서로 같기 때문에 팰린드롭입니다.
우리는 가장 긴 팰린드롭을 구해야되기 때문에, 'babab' 안에 있는 팰린드롭에서 가장 긴 길이의 투포인터를 구합니다.
코드
def answer(self,s):
#팰린드롬 판별 및 투 포인터 확장
def expand(left,right):
while left>=0 and right<len(s) and s[left]==s[right]: #팰린드롬인 경우
left-=1 #투 포인터 양옆으로 확장
right+=1
return s[left+1:right]
#해당 사항이 없을 때 빠르게 리턴
if len(s)<2 or s==s[::-1]:
return s
result=''
#슬라이딩 윈도우 우측으로 이동
for i in range(len(s)-1):
result=max(result,expand(i,i+1),expand(i,i+2),key=len)
return result
대응분석은 SAS로 수행했고 감성분석, 토픽모델링은 Google Colab 환경에서 Python 3.0으로 진행했습니다.
당시 학위논문을 쓰면서 텍스트 마이닝에 흥미를 더욱 가지며 졸업 후, Word Embedding과 Deep Learning으로 공부 영역을 확장했습니다. 현재도, 텍스트 마이닝, NLP 는 가장 관심있는 분야입니다.
그럼, 토픽모델링 CODE를 올려보도록 하겠습니다.
목차
1. 데이터 불러오기 및 형태소 분석
2. 단어 전처리
2.1. 형태소 분석에서 분할된 단어 하나로 합치기
2.2. 너무 많이 나오는 단어 제거하기
2.3. 의미없는 단어 제거 및 한 글자인 경우 제거하기
3. 기사별로 단어들을 합치기
4. 빈도수가 높은 단어, 너무 낮은 단어 제거하기
5. Gensim 패키지를 이용해 토픽모델링하기
5.1. 토픽수 구하기
5.2. 토픽모델링하기
5.3. 기사별 토픽 할당하기
1. 데이터 불러오기 및 형태소 분석
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
link = pd.read_excel('/content/drive/MyDrive/방역 기사 추출.xlsx')
link.head()
#한글제외 제거
import re
hangul = re.compile('[^ ㄱ-ㅣ가-힣]+') # 한글과 띄어쓰기를 제외한 모든 글자
for i in range(len(link)):
link.iloc[i,0] = hangul.sub(' ', link.iloc[i,0]) # 한글과 띄어쓰기를 제외한 모든 부분을 제거
#Komoran 이용하여 형태소 분석 수행
!apt-get update
!apt-get install g++ openjdk-8-jdk python-dev python3-dev
!pip3 install JPype1-py3
!pip3 install konlpy
!JAVA_HOME="C:\Users\tyumi\Downloads"
from konlpy.tag import * # class
komoran=Komoran()
for i in range(0,len(link)):
link.iloc[i,0]=re.sub('\n|\r','',link.iloc[i,0])
text_1=[]
article=[]
index=[]
paper=[]
title=[]
date=[]
for j in range(0,len(link)):
ex_pos=list(komoran.pos(link.iloc[j,0]))
for (text, tclass) in ex_pos : # ('형태소', 'NNG')
if tclass == 'VA' or tclass == 'NNG' or tclass == 'NNP' or tclass == 'MAG' :
text_1.append(text)
index+=[j]
article+=[link.iloc[j,0]]
paper+=[link.iloc[j,3]]
title+=[link.iloc[j,4]]
date+=[link.iloc[j,2]]
link=pd.DataFrame({'Index':index,'Phrase':text_1,'Text':article,'Paper':paper,'Title':title,'Date':date})
[link 데이터 프레임 예시]
2. 단어 전처리
2.1. 형태소 분석에서 분할된 단어 하나로 합치기
for i in range(0,len(link)):
if str(link.iloc[i,1])=='코로나':
if str(link.iloc[i+1,1])=='바이러스':
link.iloc[i,1]=''
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='미래':
if str(link.iloc[i+1,1])=='통합':
if str(link.iloc[i+2,1])=='당':
link.iloc[i,1]='미래통합당'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='자유':
if str(link.iloc[i+1,1])=='한국당':
link.iloc[i,1]='자유한국당'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='사회':
if str(link.iloc[i+1,1])=='거리':
if str(link.iloc[i+2,1])=='두기':
link.iloc[i,1]='거리두기'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='거리':
if str(link.iloc[i+1,1])=='두기':
link.iloc[i,1]='거리두기'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='중앙':
if str(link.iloc[i+1,1])=='방역':
if str(link.iloc[i+2,1])=='대책':
if str(link.iloc[i+3,1])=='본부':
link.iloc[i,1]=''
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
link.iloc[i+3,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='보건':
if str(link.iloc[i+1,1])=='복지':
if str(link.iloc[i+2,1])=='가족부':
link.iloc[i,1]=''
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='보건':
if str(link.iloc[i+1,1])=='복지부':
link.iloc[i,1]='보건복지부'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='박':
if str(link.iloc[i+1,1])=='능':
if str(link.iloc[i+2,1])=='후':
link.iloc[i,1]='박능후'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='정은':
if str(link.iloc[i+1,1])=='경':
link.iloc[i,1]='정은경'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='문':
if str(link.iloc[i+1,1])=='대통령':
link.iloc[i,1]='문재인'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='공공':
if str(link.iloc[i+1,1])=='의대':
link.iloc[i,1]='공공의대'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='공공':
if str(link.iloc[i+1,1])=='의료':
link.iloc[i,1]='공공의료'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='소상':
if str(link.iloc[i+1,1])=='공인':
link.iloc[i,1]='소상공인'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='자가':
if str(link.iloc[i+1,1])=='격리':
link.iloc[i,1]='자가격리'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='자가':
if str(link.iloc[i+1,1])=='진단':
link.iloc[i,1]='자가진단'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='사랑':
if str(link.iloc[i+1,1])=='제일':
if str(link.iloc[i+2,1])=='교회':
link.iloc[i,1]='사랑제일교회'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='세계':
if str(link.iloc[i+1,1])=='보건':
if str(link.iloc[i+2,1])=='기구':
link.iloc[i,1]='세계보건기구'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='박':
if str(link.iloc[i+1,1])=='시장':
link.iloc[i,1]='박원순'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='우':
if str(link.iloc[i+1,1])=='한':
link.iloc[i,1]='우한'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='강':
if str(link.iloc[i+1,1])=='대변인':
link.iloc[i,1]='강경화'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='한국':
if str(link.iloc[i+1,1])=='발':
link.iloc[i,1]='한국발'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='검':
if str(link.iloc[i+1,1])=='체':
link.iloc[i,1]='검체'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='강경':
if str(link.iloc[i+1,1])=='외교부':
if str(link.iloc[i+2,1])=='장관':
link.iloc[i,1]='강경화'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
elif str(link.iloc[i+1,1])=='외교':
if str(link.iloc[i+2,1])=='장관':
link.iloc[i,1]='강경화'
link.iloc[i+1,1]=''
link.iloc[i+2,1]=''
elif str(link.iloc[i+1,1])=='장관':
link.iloc[i,1]='강경화'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='국':
if str(link.iloc[i+1,1])=='격':
link.iloc[i,1]='국격'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='차':
if str(link.iloc[i+1,1])=='벽':
link.iloc[i,1]='차벽'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='중국':
if str(link.iloc[i+1,1])=='발':
link.iloc[i,1]='중국발'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='국민':
if str(link.iloc[i+1,1])=='힘':
link.iloc[i,1]='국민의힘'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='개천절':
if str(link.iloc[i+1,1])=='집회':
link.iloc[i,1]='개천절집회'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='광화문':
if str(link.iloc[i+1,1])=='집회':
link.iloc[i,1]='광화문집회'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='엄마':
if str(link.iloc[i+1,1])=='부대':
link.iloc[i,1]='엄마부대'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='전광훈':
if str(link.iloc[i+1,1])=='목사':
link.iloc[i,1]='전광훈목사'
link.iloc[i+1,1]=''
for i in range(0,len(link)):
if str(link.iloc[i,1])=='베이':
link.iloc[i,1]='후베이'
elif str(link.iloc[i,1])=='신천지예수교':
link.iloc[i,1]='신천지'
elif str(link.iloc[i,1])=='민주당':
link.iloc[i,1]='더불어민주당'
elif str(link.iloc[i,1])=='신천지예수교 증거장막성전':
link.iloc[i,1]='신천지'
elif str(link.iloc[i,1])=='의과대학':
link.iloc[i,1]='의대'
elif str(link.iloc[i,1])=='대한의사협회':
link.iloc[i,1]='의협'
elif str(link.iloc[i,1])=='중동호흡기증후군':
link.iloc[i,1]='메르스'
elif str(link.iloc[i,1])=='비대':
link.iloc[i,1]='비대면'
elif str(link.iloc[i,1])=='우하':
link.iloc[i,1]='우한'
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
dd = pd.read_excel('/content/drive/MyDrive/제거문자.xlsx')
def find_index(data, target):
res = []
lis = data
while True:
try:
res.append(lis.index(target) + (res[-1]+1 if len(res)!=0 else 0)) #+1의 이유 : 0부터 시작이니까
lis = data[res[-1]+1:]
except:
break
return res
aa=[]
for i in range(0,len(dd)):
aa+=find_index(link.iloc[:,1].tolist(),dd.iloc[i,0])
for j in range(0,len(aa)):
link.iloc[aa[j],1]=''
ii=[]
for i in range(0,len(link)):
if link.iloc[i,1]!='':
ii+=[i]
link_1=link.iloc[ii,:]
for i in range(0,len(link_1)):
if len(link_1.iloc[i,1])==1:
link_1.iloc[i,1]=''
ii=[]
for i in range(0,len(link_1)):
if link_1.iloc[i,1]!='':
ii+=[i]
link_2=link_1.iloc[ii,:]
link_2
[link_2 데이터프레임 예시]
3. 기사별로 단어들을 합치기
!pip3 install gensim
import gensim
link_2=link_2.reset_index(drop=True)
grouped =link_2.groupby(['Index'])
for key, group in grouped:
globals()['Phrase_{}'.format(key)]=list(group.Phrase)
globals()['Index_{}'.format(key)]=list(group.Index)[0]
globals()['Text_{}'.format(key)]=list(group.Text)[0]
globals()['Title_{}'.format(key)]=list(group.Title)[0]
globals()['Paper_{}'.format(key)]=list(group.Paper)[0]
globals()['Date_{}'.format(key)]=list(group.Date)[0]
Phrase=[]
Index=[]
Text=[]
Title=[]
Paper=[]
Date=[]
for key in range(470):
Phrase.append(globals()['Phrase_{}'.format(key)])
Index.append(globals()['Index_{}'.format(key)])
Text.append(globals()['Text_{}'.format(key)])
Title.append(globals()['Title_{}'.format(key)])
Paper.append(globals()['Paper_{}'.format(key)])
Date.append(globals()['Date_{}'.format(key)])
link_3=pd.DataFrame({'Index':Index,'Phrase':Phrase,'Text':Text,'Title':Title,'Paper':Paper,'Date':Date})
link_3
[link_3 데이터프레임 예시]
4. 빈도수가 높은 단어, 너무 낮은 단어 제거하기
from gensim import corpora
tokenized_doc = link_3.Phrase
dictionary = corpora.Dictionary(tokenized_doc)
dictionary.filter_extremes(no_below=5,no_above=0.8)
text=tokenized_doc
corpus = [dictionary.doc2bow(text) for text in tokenized_doc]
5. Gensim 패키지를 이용해 토픽모델링하기
5.1. 토픽수 구하기
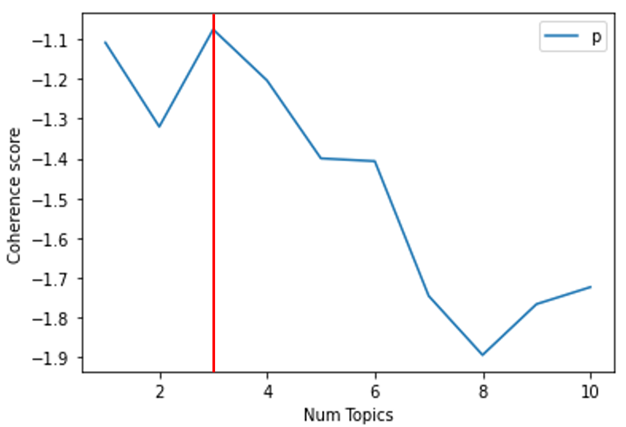
#토픽모델링-토픽수
per=[]
import matplotlib.pyplot as plt
from gensim import models
for i in range(1,11):
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = i, id2word=dictionary, passes=500,random_state=2500,gamma_threshold=0.01,alpha='auto')
cm = models.CoherenceModel(model=ldamodel, corpus=corpus, coherence='u_mass')
coherence = cm.get_coherence()
per.append(coherence)
limit=11; start=1; step=1;
x = range(start, limit, step)
plt.plot(x, per)
plt.xlabel("Num Topics")
plt.ylabel("Coherence score")
plt.legend(("per"), loc='best')
plt.show()
[토픽 수 그래프]
5.2. 토픽모델링하기
NUM_TOPICS = 3
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = NUM_TOPICS, id2word=dictionary, passes=500,random_state=2500,gamma_threshold=0.01,alpha='auto')
topics = ldamodel.print_topics(num_words=20)
for topic in topics:
print(topic)
5.3. 기사별 토픽 할당하기
#토픽모델링-문서
def make_topictable_per_doc(ldamodel, corpus):
topic_table = pd.DataFrame()
for i, topic_list in enumerate(ldamodel[corpus]):
doc = topic_list[0] if ldamodel.per_word_topics else topic_list
doc = sorted(doc, key=lambda x: (x[1]), reverse=True)
for j, (topic_num, prop_topic) in enumerate(doc):
if j == 0:
topic_table = topic_table.append(pd.Series([int(topic_num), round(prop_topic,4), topic_list]), ignore_index=True)
else:
break
return(topic_table)
topictable = make_topictable_per_doc(ldamodel, corpus)
topictable = topictable.reset_index()
a=topictable.iloc[:,0]
b=topictable.iloc[:,1]
c=topictable.iloc[:,2]
link_3['Topic']=b.tolist()
link_3['Frequency']=c.tolist()
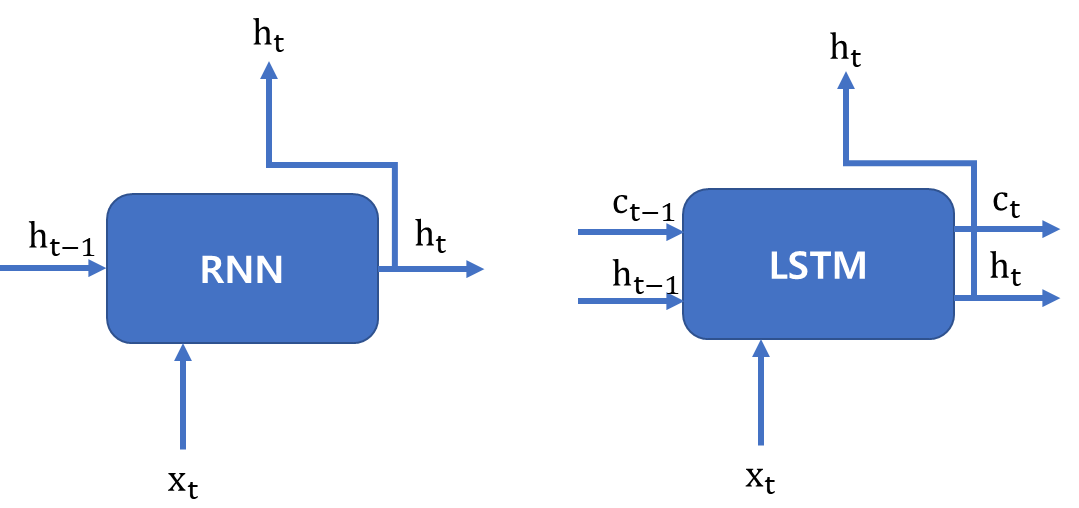
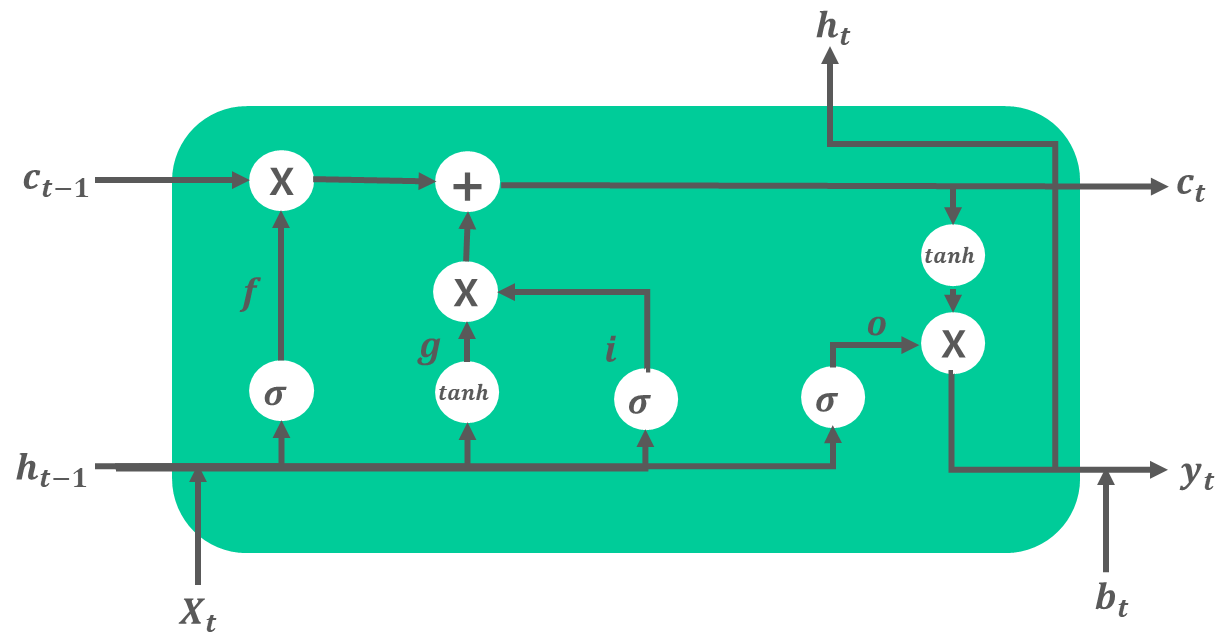
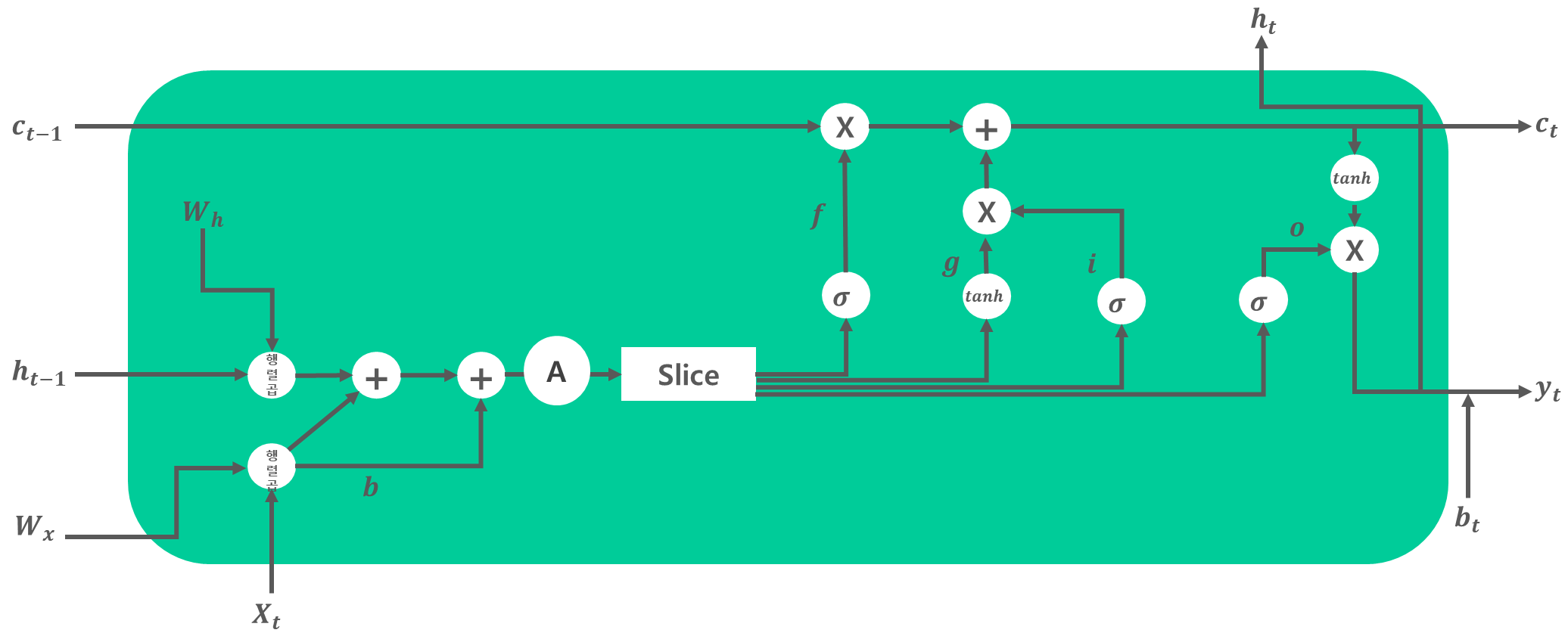
LSTM은 RNN의 기울기 소실 문제를 방지하는 신경망입니다. RNN의 Hidden Layer에 기억 셀, Input/Output/Forget Gate를 추가한 형태입니다.
LSTM과 RNN의 차이는 [그림 1]로 설명하겠습니다.
RNN의 Hidden Layer에는 Hidden State인 Ht-1과 Input인 Xt, 가중치인 Wt로 구성되어 있습니다. 이들은 Hidden Layer 안에서 선형결합과 하이퍼볼릭 탄젠트 함수를 거친 후 Ht를 내보냅니다.
하지만 LSTM의 Hidden Layer에는 기억 셀인 Ct-1과 Input/Output/Forget Gate가 있습니다. 기억 셀은 데이터를 LSTM 계층 내에서만 주고받습니다. 즉, LSTM 계층 내에서만 이동하고 다른 계층으로 출력하지는 않습니다. 또한 기억 셀 Ct에는 시각 t에서의 LSTM의 기억이 저장돼 있습니다. 이것은 과거로부터 시각 t까지에 필요한 모든 정보가 저장돼 있다고 가정합니다. 이 기억을 바탕으로 다음 시각의 LSTM에 Hidden State Ht를 출력합니다.
[그림 1] RNN과 LSTM의 차이
2. LSTM 대략적인 설명
지금부터 LSTM의 게이트에서 일어나는 과정을 대략적으로 설명해보겠습니다.
[그림 2] LSTM 구조
1) o : Output Gate
Output Gate는 다음 Hidden State Ht의 출력을 담당하는 게이트입니다. Output Gate에서 Hidden State Ht-1과 Input Xt를 연산한 것을 tanh(Ct)에 곱합니다. 이를 통해 tanh(Ct)에서 얼만큼의 양을 Ht로 출력시킬지 결정합니다.
계산식은 [식 1]과 같습니다. 가중치와 Xt, Ht-1간의 선형결합에 시그모이드 함수를 씌운 형태입니다. [식 2]는 Output Gate 결과에 tanh(Ct)를 곱해 Hidden State Ht로 생성하는 과정입니다.
[식 1] Output Gate[식 2] Hidden State Ht 구하는 방식
2) f : Forget Gate
Forget Gate는 이전 단계에서의 기억 셀 Ct-1에서 불필요한 기억을 잊게 해주는 게이트입니다. Forget Gate에서 Ht-1과 Xt를 연산한 것을 Ct-1에 곱합니다. 이를 통해 Ct-1에서 얼만큼의 양을 지워서 Ct로 연산할지 결정합니다.
계산식은 [식 3]와 같습니다. [식 4]는 Forget Gate 결과에 Ct-1를 곱해 기억 셀 Ct로 생성하는 과정입니다.
[식 3] Forget Gate[식 5] 기억 셀 Ct를 구하는 방식
3) g : 기억 셀에 추가하는 새로운 기억
새로 기억해야 할 정보를 기억셀에 추가하기 위해 [그림 2]에서와 같이 tanh 노드를 추가합니다. [그림 2]에서 tanh노드와 이전 단계의 기억 셀 Ct-1을 더하면서 기억 셀에 새로운 '정보'가 추가됩니다.
계산식은 [식 5]와 같습니다. 이 g가 Ct-1에 더해짐으로써 새로운 기억이 생깁니다.
[식 5] 기억 셀에 추가하는 새로운 기억 g 계산
4) i : Input Gate
Input Gate는 g의 각 원소가 새로 추가되는 기억으로써의 가치가 얼마나 큰지를 판단합니다. 새 기억 g를 모두 수용하지 않고, 적절히 부분적으로 선택하는 것이 이 게이트의 목표입니다.
계산식은 [식 6]과 같습니다.
[식 6] Input Gate&amp;amp;amp;amp;amp;nbsp;
앞에서 구한 i, g, f를 이용해서 이전 단계에서의 기억 셀 Ct-1을 Ct로 변환하는 과정은 [식 7]과 같습니다.
[식 7] 기억 셀 Ct를 구하는 방식
[그림 2] LSTM 구조
정리하자면, [그림 2]에서 LSTM은 RNN과 다르게 필요한 정보(기억)를 선별해서 저장하는 과정을 거칩니다.
즉, 이전 단계에서의 기억셀 Ct-1에 f를 적용해 일부 기억을 잊고, g와 i의 곱을 더해 새로운 기억을 추가합니다. 이후 tanh()을 씌우고 o를 적용해 어느 정도의 데이터를 Hidden State Ht로 출력할지 결정합니다.
3. LSTM 구현
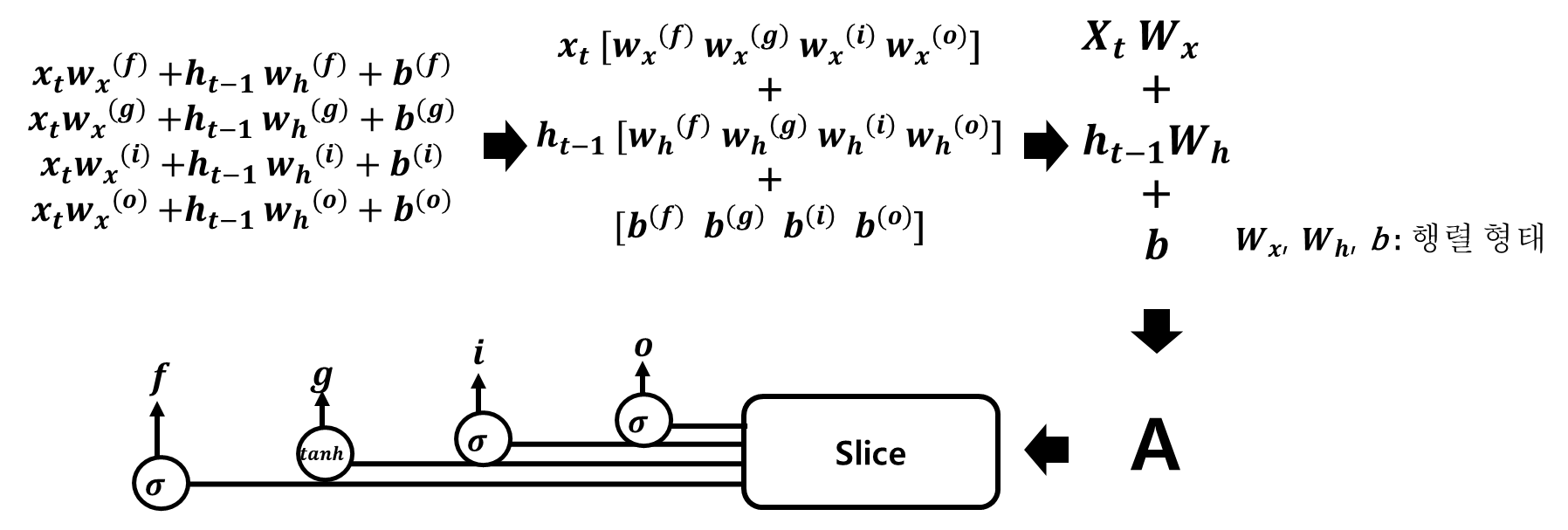
[식 8]은 LSTM에서 수행하는 계산입니다. [식 8]의 위에서 네 개의 수식은 XWx+hWh+b 형태의 아핀 변환입니다. 이것을 하나의 식으로 정리해 계산할 수 있습니다. 그 과정은 [그림 3]과 같습니다.
[식 8] LSTM 수식
[그림 3] 각 식의 가중치들을 모아 4개의 식을 단 한번의 아핀 변환으로 계산
[그림 3]은 각 식의 가중치들을 모아 4개의 식을 단 한번의 아핀 변환으로 계산해 A 행렬을 구합니다. 이후 Slice를 이용해 활성화 함수를 적용해서 f, g, i, o 를 생성합니다. 이와 같이 계산하면 원래 개별적으로 총 4번을 수행하던 아핀 변환을 1번의 계산으로 끝마칠 수 있습니다. 이것을 반영해 LSTM을 표현하면 [그림 4]와 같습니다.
[그림 4] 4개분의 가중치를 모아 아핀 변환을 수행하는 LSTM의 계산 그래프
[그림 4]에서와 같이 처음 4개의 아핀 변환을 한 번에 수행합니다. 그리고 Slice 노드를 통해 4개의 결과를 꺼냅니다. Slice는 아핀 변환의 결과를 균등하게 네 조각으로 나눠서 꺼내주는 노드입니다. Slice 다음에는 활성화 함수를 거쳐 계산을 수행해 기억 셀 Ct, Hidden State Ht를 구합니다.
4. LSTM 구현[파이썬]
코드는 '밑바닥부터 시작하는 딥러닝2'의 'Common/time_layers.py' 에 있습니다.
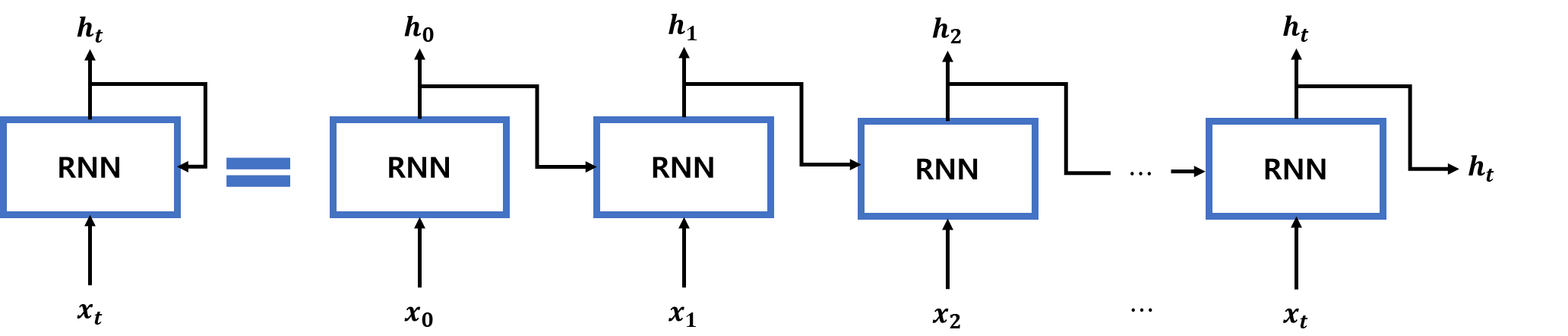
RNN(Recurrent Neural Network)로, 은닉층에서 나온 결과값이 다시 은닉층으로 돌아가 새로운 입력값과 연산을 수행하는 순환구조입니다. 완전연결층(Fully Connected Layer), CNN(Convolutional Neural Network)은 은닉층에서 나온 결과값이 출력층 방향으로 이동하지만, RNN은 은닉층으로 되돌아가 순환한다는 점에서 큰 차이가 있습니다.
RNN은 [그림 1]과 같은 순환구조를 형성합니다.
[그림 1] RNN의 순환구조
[그림 1]은 RNN 순환구조를 펼친 형태로 입력값{x0, x1,..., xt}를 순차적으로 입력했을 때 각 입력에 대응해 {h0,...,ht}가 출력됩니다. 이때 RNN계층은 모두 같은 계층이고 출력{h0,..,hk,.,ht}를 각각 k 시점에서의 은닉 상태라고 합니다.
이러한 RNN의 구조는 시계열 데이터, 텍스트 데이터에 적합합니다.
가령 'You say goodbye and I say hello'에서 각 단어의 다음에 나올 단어를 예측하고자 할때, 문장에서 임베딩 된 단어를 순차적으로 RNN 에 입력합니다.
이후 각 입력에 대응하는 은닉상태로 다음에 나올 단어를 예측합니다. 여기서 은닉상태는 해당 시점까지의 단어 정보를 나타냅니다.
순전파와 역전파를 반복하며 모형을 학습시켜 최종적으로 각 단어 다음에 나올 단어를 완벽하게 예측하는 은닉상태를 갖는 것이 RNN의 목적 중 하나입니다.
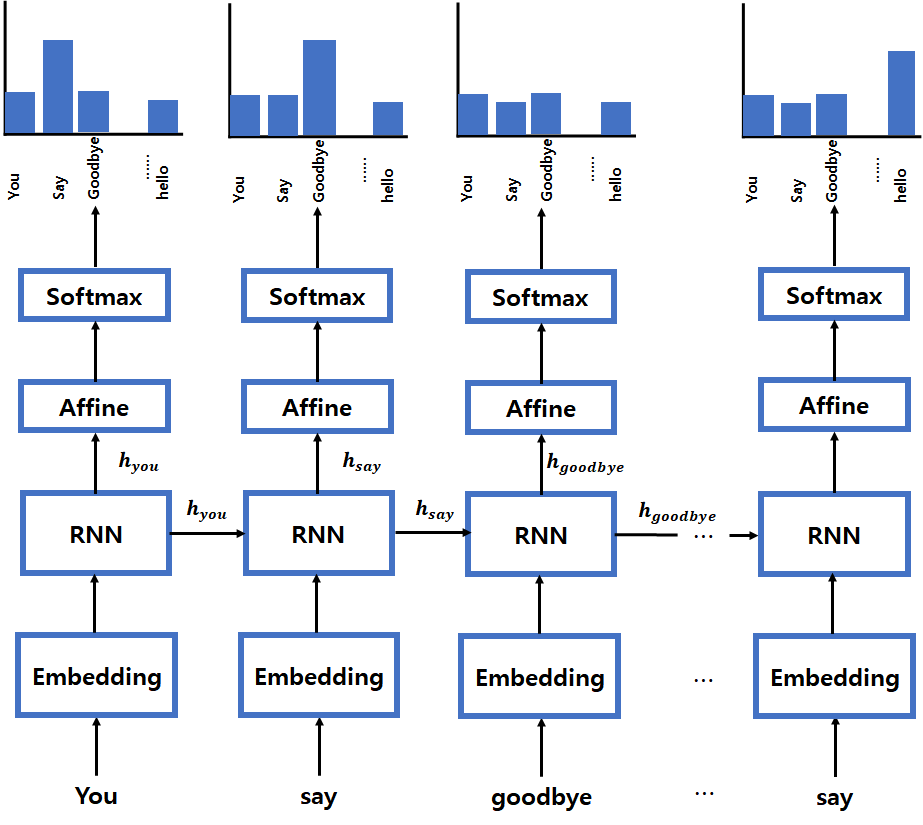
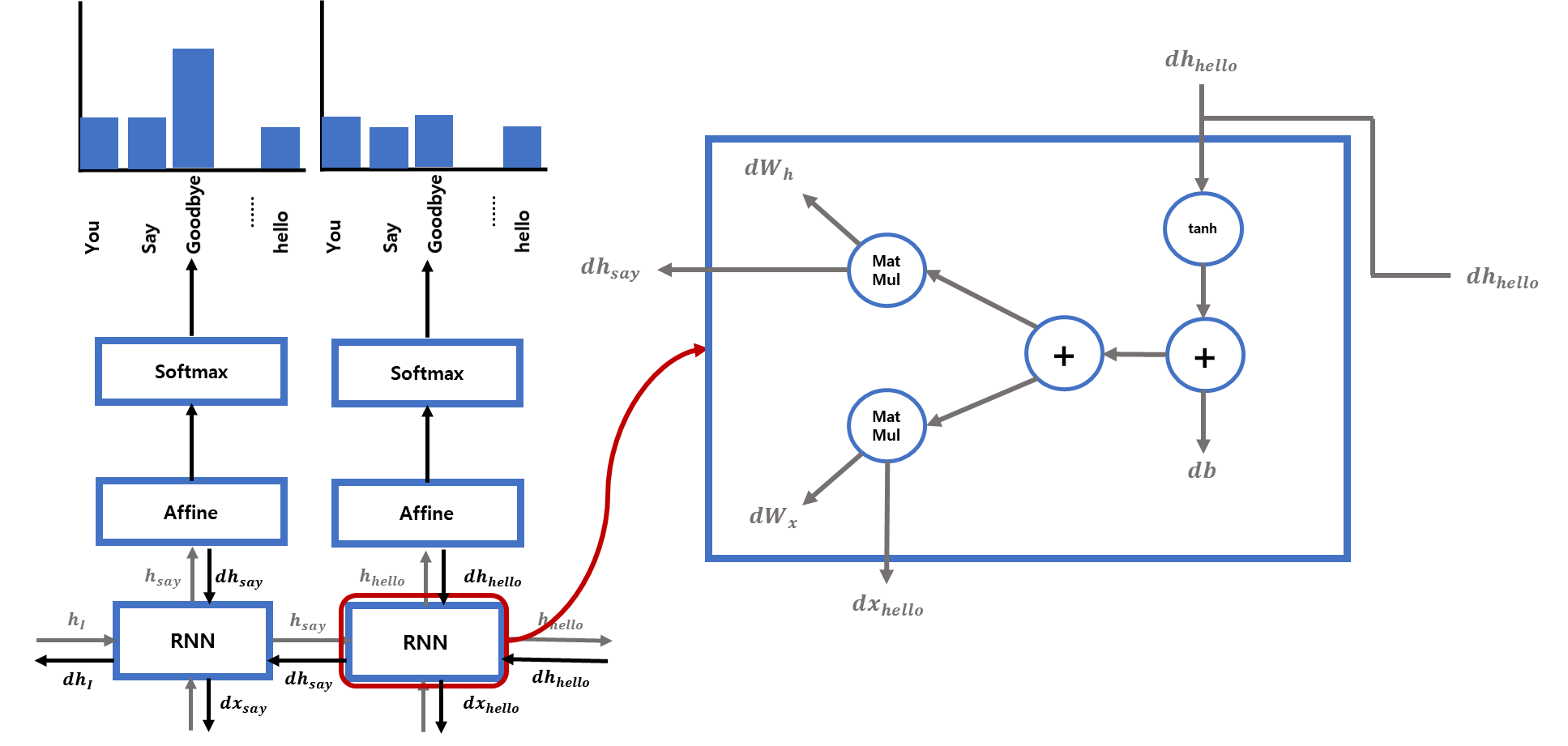
[그림 2]는 'You say goodbye and I say hello'에서 각 단어 다음에 나올 단어를 예측하며 학습시킨 RNN 언어모델입니다.
[그림 2] RNN의 언어 모델
[그림 2]에서 You 라는 단어가 Embedding 계층을 거친 후 RNN에 입력되면, you의 은닉상태 h_you를 출력하고 다음에 올 단어
say를 예측합니다. 은닉상태 h_you는 다음 RNN 계층으로 들어가 say라는 단어가 임베딩된 형태와 연산합니다. 여기서 h_you는 과거의 정보 'you'를 응집한 은닉 상태입니다.
다음 RNN 계층에서 나온 say의 은닉상태 h_say는 과거의 정보 'You say'를 응집한 은닉 상태입니다. 이후 h_say를 이용해 다음에 올 단어 goodbye를 예측합니다.
이 과정이 RNN 학습, 순전파 과정입니다. 이후 역전파 과정을 거치며 예측 단어와 실제 단어를 비교하면서 가중치와 은닉상태를 업그레이드합니다.
2. 알고리즘
2.1 순전파
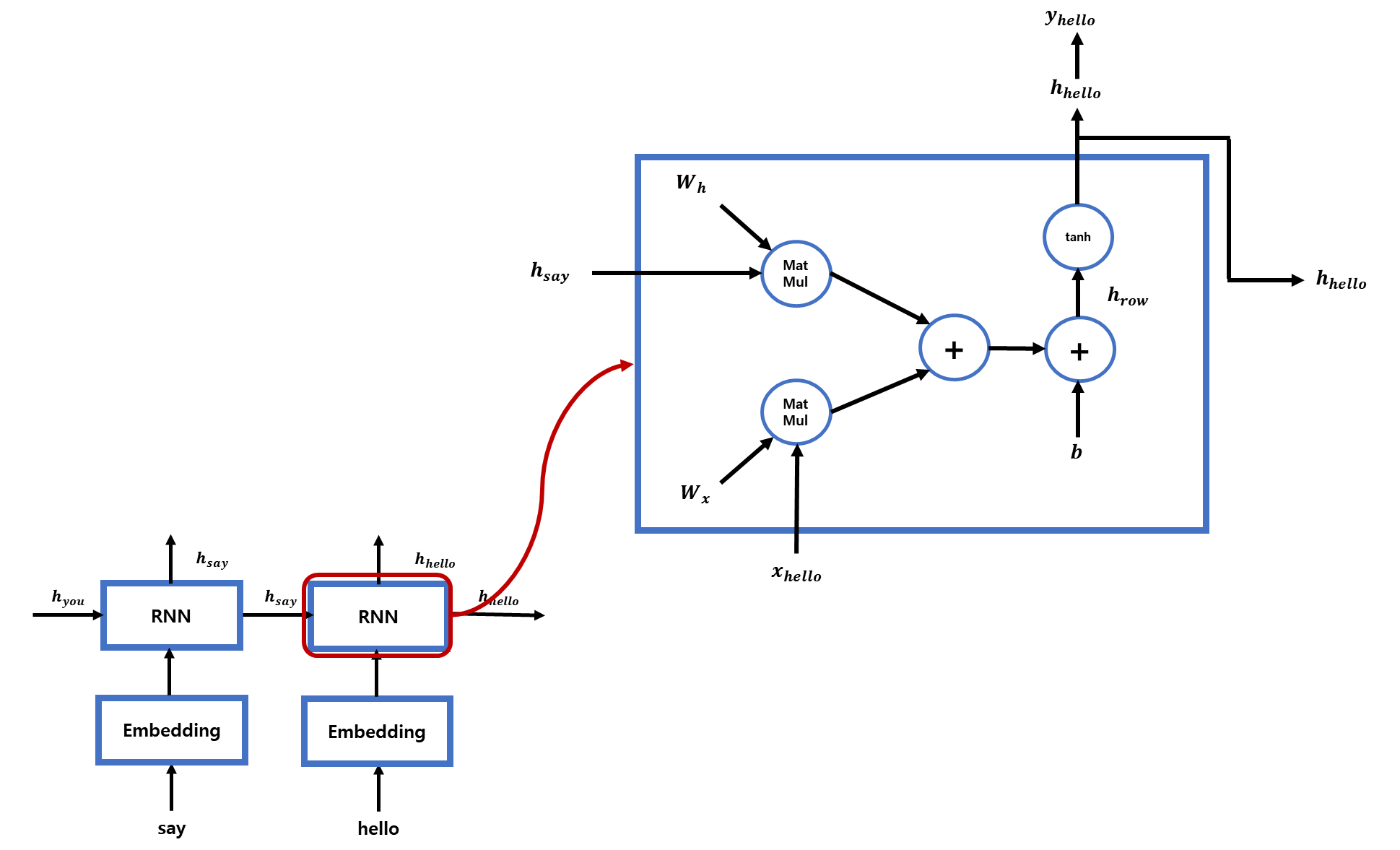
[그림 3] RNN 순전파 과정
[그림3]은 RNN의 순전파 과정입니다. ('You say goodbye and I say hello'에서 다음에 나올 단어를 예측하며 RNN 계층을 학습하는 과정입니다.)
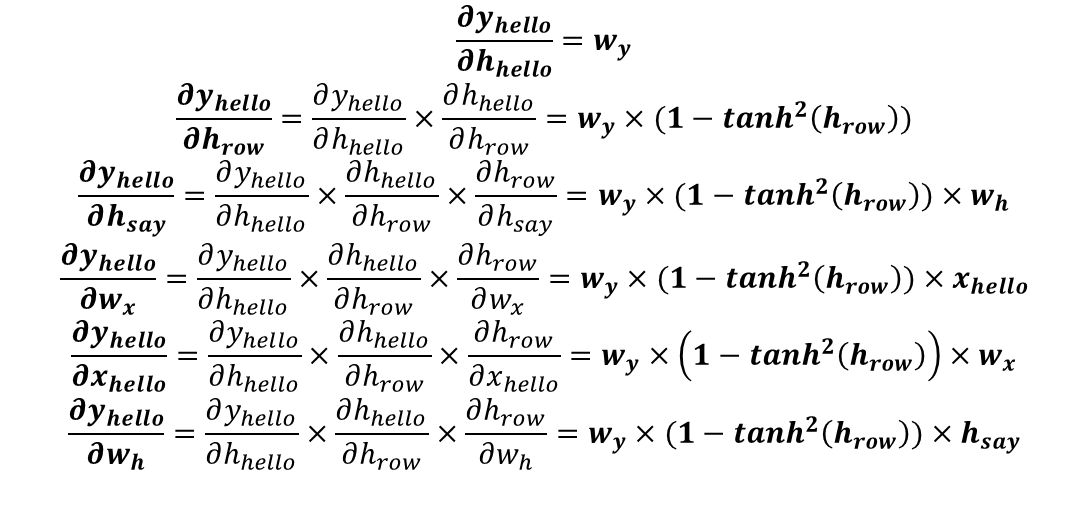
1) say의 은닉상태인 h_say와 hello가 임베딩된 벡터(x_hello)가 RNN계층에 들어간 후 일련의 과정을 통해 hello의 은닉상태인 h_helllo와 y_hello를 출력합니다.
2) 출력된 은닉상태는 다음 RNN 계층의 입력으로 이동합니다.
3) h_hello는 hello를 비롯해 say, I 와 같이 그동안 이동해온 단어들의 정보를 갖고있습니다.
4) y_hello는 h_hello가 변형된 형태로, hello의 다음 단어를 예측한 결과입니다.
여기서 일련의 과정은 [그림4]의 식으로, 모형으로 나타내면 [그림3]의 오른쪽 직사각형입니다.
[그림 4] RNN 순전파 수식
1) 가중치와 편향인 Wh, Wx, b는 RNN계층별로 동일합니다.
2) [그림 4]를 보면 h_hello를 구하기 위해 h_say와 Wh를 곱하고 hello를 임베딩한 단어벡터(x_hello)와 Wx를 곱한 후 편향(b)을 더했습니다.
from google.colab import files
myfile = files.upload()
import io
import pandas as pd
dict_0 = pd.read_excel(io.BytesIO(myfile['Bing 번역 최종.xlsx']))
dict_0.head()
감성사전 예시
3. 감성 사전 품사 추출하기
from konlpy.tag import * # class
komoran=Komoran()
index=[]
words=[]
score=[]
text_1=[]
for j in range(0,len(dict_0)):
ex_pos=komoran.pos(dict_0.iloc[j,0])
for (text, tclass) in ex_pos : # ('형태소', 'NNG')
if tclass == 'VV' or tclass == 'VA' or tclass == 'NNG' or tclass=='XPN' or tclass == 'NNP'or tclass=='VX' or tclass == 'VCP' or tclass == 'VCN' or tclass == 'MAG' or tclass == 'XR':
index+=[j]
words+=[dict_0.iloc[j,0]]
score+=[dict_0.iloc[j,1]]
text_1.append(text)
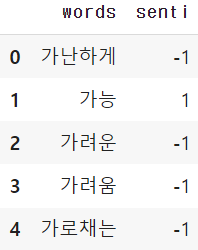
dict_1=pd.DataFrame({'Index':index,'Text':text_1,'Words':words,'Score':score})
품사 추출한 감성사전 예시
4. 방역 기사 불러오기
from google.colab import files
myfile = files.upload()
import io
import pandas as pd
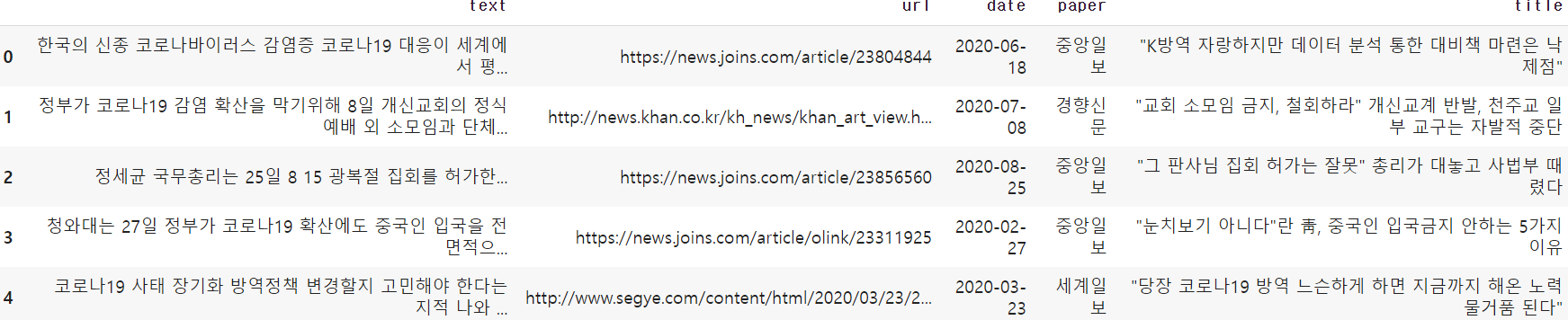
article_0 = pd.read_excel(io.BytesIO(myfile['방역 기사 추출.xlsx']))
article_0.head()
방역 기사 예시
5. 방역 기사 품사 추출하기
import re
index=[]
paper=[]
text_1=[]
text_2=[]
title=[]
for i in range(0,len(article_0)):
article_0.iloc[i,0]=re.sub('\n|\r','',article_0.iloc[i,0]) #문장에서 필요없는 문구 삭제
ex_pos=komoran.pos(article_0.iloc[i,0]) #komoran 품사 태그 적용
for (text, tclass) in ex_pos : # ('형태소', 'NNG')
if tclass == 'VV' or tclass == 'VA' or tclass == 'NNG' or tclass == 'NNP'or tclass=='XPN' or tclass=='VX' or tclass == 'VCP' or tclass == 'VCN' or tclass == 'MAG' or tclass == 'XR':
index+=[i]
paper+=[article_0.iloc[i,3]]
text_1+=[article_0.iloc[i,0]]
text_2.append(text)
title+=[article_0.iloc[i,4]]
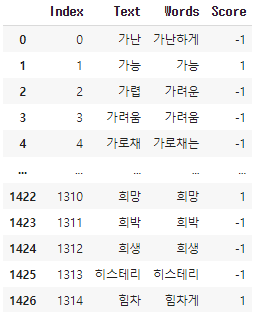
article_1=pd.DataFrame({'Index':index,'Text':text_2,'Article':text_1,'Paper':paper,'Title':title})
품사 추출된 방역 기사 예시
6. 기사에 감성을 적용해, 감성 점수 구하기
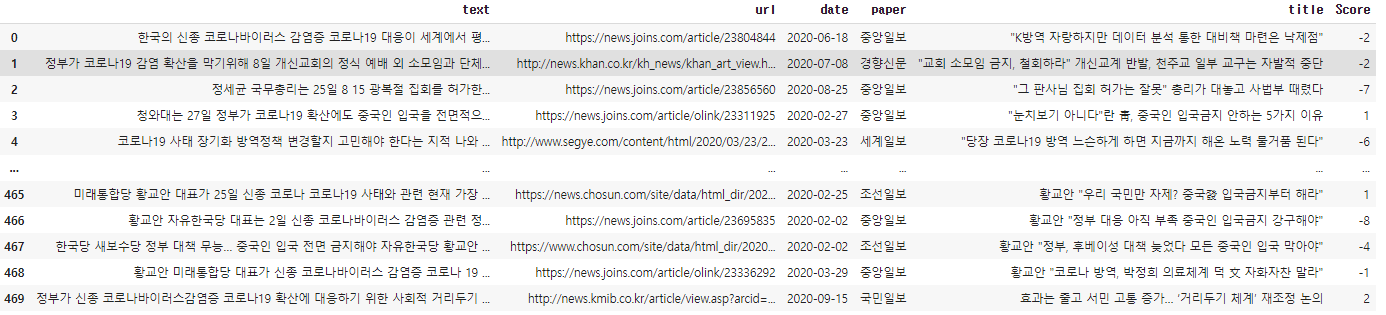
6-1. 방역 기사 속 품사들과 사전 속 품사를 매치하여 감성 점수를 구하기
article_1.loc[:,'Score']=[0]*len(article_1)
dict_list=list(dict_1.loc[:,'Text'])
article_list=list(article_1.loc[:,'Text'])
for i in range(len(dict_list)):
equal_list = list(filter(lambda x: (article_list[x]==dict_list[i]) and (len(article_list[x])>=2), range(len(article_list))))
for j in equal_list:
article_1.loc[j,'Score']=dict_1.loc[i,'Score']
1과 2에서 언어모델을 설명한 후, 3에서 언어모델로 적합한 기법이 RNN임을 강조하며 필요성을 설명드리겠습니다.
언어모델을 이미 아는 분이시면 3으로 바로 넘어가주세요 :)
순서는 아래와 같습니다.
1. 언어모델이란?
2. 수식으로 표현한 언어모델
3. 언어모델 관점, RNN의 필요성
1. 언어모델이란?
언어모델은 문장에 대해서, 그 문장이 얼마나 자연스러운지를 확률로 평가하는 것입니다.
예를 들면, '나는 학교에 간다'라는 문장에는 높은 확률을 출력하고 '나는 학교에 갈매기'에는 낮은 확률을 출력하는 것이 일종의 언어모델입니다.
언어모델은 기계번역과 음성인식에 대표적으로 이용됩니다. 하지만 새로운 문장을 생성하는 용도로도 사용할 수 있습니다. 왜냐하면 언어모델은 단어 순서가 얼마나 자연스러운지를 확률적으로 평가할 수 있기 때문입니다. 따라서 해당 확률분포에 따라 다음 순서에 올 적합한 단어를 샘플링할 수 있습니다.
이제 언어모델을 수식으로 설명하겠습니다.
2. 수식으로 표현한 언어모델
w1,...,wm이라는 m개의 단어로 된 문장이 있을 때, 단어가 w1,...,wm순서로 등장할 확률을 P(w1,...,wm)이라고 합니다.
이 확률은 동시확률이라고도 합니다. 우리는 이 확률을 구해서 문장의 자연스러운 정도를 계산합니다.
동시확률 P(w1,...,wm)은 사후 확률을 사용해 [식 1]과 같이 분해하여 쓸 수 있습니다. [식 1]의 사후확률은 타깃 단어보다 왼쪽에 있는 모든 단어를 조건으로 했을 때의 확률입니다. 이러한 사후확률을 총곱해서 나온 것이 언어모델의 동시확률입니다.
[식 1]
3. 언어모델 관점, RNN의 필요성
Word2Vec의 CBOW 모델을 언어 모델에 적용했을 때 나타나는 문제점(단어의 순서를 반영하지 않는 점)과 신경 확률론적 언어모델(NPLM)에서 제안한 모델의 문제점(단어가 늘어날수록 가중치가 증가하는 점)을 해결하기 위해 등장한 것이 RNN 언어모델입니다.
1) CBOW 모델을 이용한 언어모델
CBOW 모델을 억지로 언어모델에 적용하려면 맥락크기를 특정 값으로 한정하여 근사적으로 나타냅니다. [식 2]는 맥락을 왼쪽 2개의 단어로 한정합니다.
[식 2]
맥락 크기를 특정 값으로 한정하여 나타내면, 맥락 바깥의 정보는 반영되지 않습니다.
그리고 문제점이 더 있습니다. 바로 CBOW 모델에서는 맥락 안의 단어 순서가 무시된다는 점입니다.
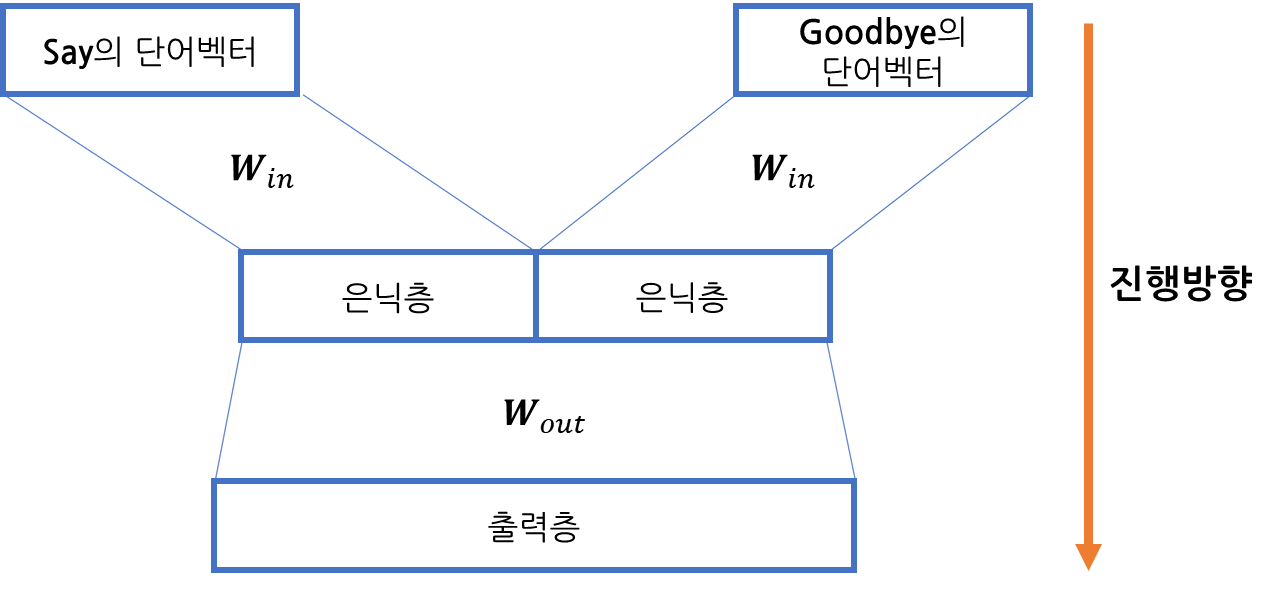
만약 맥락크기가 2일때, 'I say goodbye, you say hello' 문장에서 'you' 예측에는 어떻게 CBOW 모델을 사용할까요? 맥락인 'say, goodbye'를 이용하고 [그림 1]과 같습니다.
[그림 1]
[그림 1]에서 모델의 은닉층에서는 'say'와 'goodbye' 단어 벡터들이 더해지므로 맥락의 단어 순서는 무시됩니다.
2) NPLM(Neural Probabilistic Language Model) 에서 제안한 언어모델
[그림 2]
맥락의 단어 벡터 순서를 고려하기 위해 [그림 2]와 같이 은닉층에서 단어 벡터를 연결하는 방식이 있습니다. 하지만 이 방식을 취하면, 맥락크기에 비례해서 가중치가 늘어나는 문제점이 생깁니다.
3) RNN의 필요성
RNN은 맥락이 아무리 길어도 그 맥락의 정보를 기억하는 구조로, 순서가 있는 시계열 데이터에도 유연하게 대응할 수 있습니다. 따라서 주어진 문장의 정보를 습득하며 학습한 후, 다음에 올 단어를 예측할 수 있습니다.
from itertools import product
def solution(numbers, target):
l = [(x, -x) for x in numbers]
s=list(map(sum,product(*l)))
return s.count(target)
solution([1,1,1,1,1],3)
풀이과정
설명을 위해 중간에 print 함수를 추가했습니다.
from itertools import product
def solution(numbers, target):
l = [(x, -x) for x in numbers]
s = list(product(*l))
ss=list(map(sum,product(*l)))
print(l)
print(s)
print(ss)
return ss.count(target)
solution([1,1,1,1,1],3)
[1,1,1,1,1]을 numbers로, 3을 target으로 할 때, solution 함수의 print(l), print(s), print(ss), 결과값은 아래와 같습니다.
print(l)을 통해 numbers의 각 숫자와 마이너스 형태를 취한 숫자를 튜플 형태로 나타냈습니다.
list(product(*l))을 통해 (1,1,1,1,1) 부터 (-1,-1,-1,-1,-1) 까지 1과 -1로 구성할 수 있는 배열을 튜플 형태로 나타냈습니다.
마지막으로 map과 sum 함수를 이용해 앞에서 구한 배열을 합쳤습니다. 예를 들면, (1,1,1,1,1)은 5가 되는 것입니다.