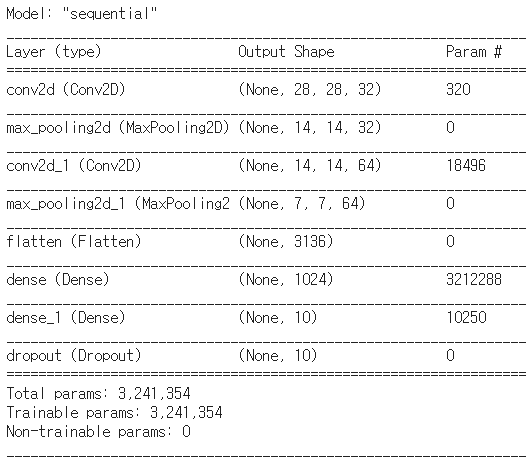
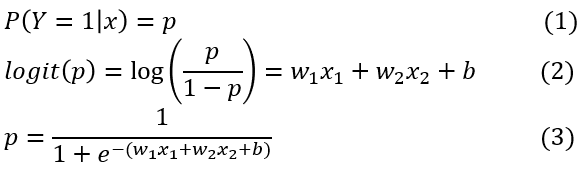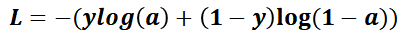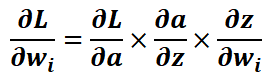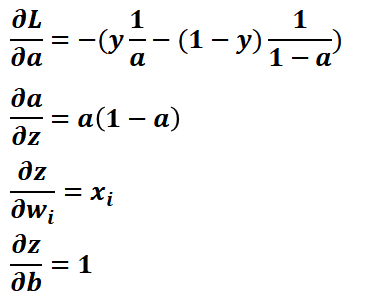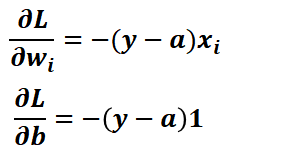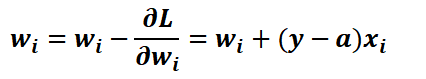def solution(lottos, win_nums):
count_same=0
count_mask=0
answer=[]
for i in range(len(lottos)):
if lottos[i] in win_nums:
count_same+=1
elif lottos[i]==0:
count_mask+=1
return [len(lottos)+1-(count_same+count_mask) if len(lottos)+1-(count_same+count_mask)<=6 else 6,
len(lottos)+1-count_same if len(lottos)+1-count_same<=6 else 6]
def solution(orders, course):
from itertools import combinations
from collections import Counter
total=[]
result=[]
value_1=[]
for j in course:
total=[]
value_1=[]
for i in orders:
total+=list(combinations(i, j))
for idx, value in enumerate(total):
value_1.append(''.join(sorted(list(value))))
for common in Counter(value_1).most_common():
if common[1]==Counter(value_1).most_common()[0][1] & Counter(value_1).most_common()[0][1]>1:
result.append(common[0])
return sorted(list(set(result)))
1단계: itertools.combinations 함수로 음식 조합을 구성합니다.
2단계: 1단계의 결과가 튜플 형식으로 나옵니다. 그리고 ('A', 'B'), ('C', 'D') 형식이기 때문에 'AB', 'CD'로 변환합니다.
3단계: 두 명 이상이 주문한 음식 조합을 선택해야 됩니다. 또한 만약에 같은 개수의 음식 조합이 존재한다면, 주문한 수가 가장 많은 음식 조합을 선택해야 합니다. 예를 들면, 네오와 어피치가 'ABC' 음식 조합을 먹었고 네오, 어피치, 프로도가 'ACE' 음식 조합을 먹었다면 'ACE'를 선택해야 합니다. 주문한 수가 더 많았기 때문입니다.
따라서 collections.Counter 함수를 이용해서 2번 이상 주문하고 가장 많이 주문한 조합 위주로 선택해야 합니다.
4단계: set 함수를 이용해 중복된 결과를 제거하고 list 변환한 후 sorted 함수로 알파벳순 정렬합니다.
카카오에 입사한 신입 개발자 네오는 "카카오계정개발팀"에 배치되어, 카카오 서비스에 가입하는 유저들의 아이디를 생성하는 업무를 담당하게 되었습니다. "네오"에게 주어진 첫 업무는 새로 가입하는 유저들이 카카오 아이디 규칙에 맞지 않는 아이디를 입력했을 때, 입력된 아이디와 유사하면서 규칙에 맞는 아이디를 추천해주는 프로그램을 개발하는 것입니다. 다음은 카카오 아이디의 규칙입니다.
아이디의 길이는 3자 이상 15자 이하여야 합니다.
아이디는 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.) 문자만 사용할 수 있습니다.
단, 마침표(.)는 처음과 끝에 사용할 수 없으며 또한 연속으로 사용할 수 없습니다.
"네오"는 다음과 같이 7단계의 순차적인 처리 과정을 통해 신규 유저가 입력한 아이디가 카카오 아이디 규칙에 맞는 지 검사하고 규칙에 맞지 않은 경우 규칙에 맞는 새로운 아이디를 추천해 주려고 합니다. 신규 유저가 입력한 아이디가 new_id 라고 한다면,
1단계 new_id의 모든 대문자를 대응되는 소문자로 치환합니다.
2단계 new_id에서 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.)를 제외한 모든 문자를 제거합니다.
3단계 new_id에서 마침표(.)가 2번 이상 연속된 부분을 하나의 마침표(.)로 치환합니다.
4단계 new_id에서 마침표(.)가 처음이나 끝에 위치한다면 제거합니다.
5단계 new_id가 빈 문자열이라면, new_id에 "a"를 대입합니다.
6단계 new_id의 길이가 16자 이상이면, new_id의 첫 15개의 문자를 제외한 나머지 문자들을 모두 제거합니다.
만약 제거 후 마침표(.)가 new_id의 끝에 위치한다면 끝에 위치한 마침표(.) 문자를 제거합니다.
7단계 new_id의 길이가 2자 이하라면, new_id의 마지막 문자를 new_id의 길이가 3이 될 때까지 반복해서 끝에 붙입니다.
풀이
[정규표현식을 이용했습니다]
def solution(new_id):
import re
new_id=''.join(list(re.sub('^[.]|[.]$','',re.sub('[.]{2,}','.',re.sub('[^0-9a-z._-]','',new_id.lower())))))
if len(new_id)==0: new_id='a'
elif len(new_id)>=16: new_id=re.sub('[.]$','',new_id[:15])
while len(new_id)<3: new_id=new_id+new_id[-1]
return new_id
문제의 1~7단계 순서대로 설명드리겠습니다.
1단계: lower() 함수로 대문자->소문자 변경
2단계: re 의 sub() 함수로 숫자, 소문자, . , _ , - 제외한 나머지 문자는 공백처리
3단계: . 이 두 개 이상인 경우 . 하나로 처리 re.sub('[.]{2,}','.', 문자열)
4단계: ^[.] 이용, . 이 앞에 있으면 공백처리, [.]$ 이용, . 이 끝에 있으면 공백처리
5단계: 문자열의 개수를 세어야 된다. 파이썬에서 길이를 재는 len함수는 ' ' 를 0이 아닌, 칸 수만큼 개수를 내보낸다.
따라서 ''.join(list(...))를 이용해 문자열 -> 리스트 -> 공백이 없는 문자열로 변환한다.
6단계: 문자열의 개수가 16개 이상이면 15개까지 잘라낸다. 이후 [.]$ 이용, . 이 끝에 있으면 공백처리
7단계: 문자열의 개수가 3보다 작으면 문자열 개수가 3이 될때까지 마지막 문자열을 문자열 끝에 붙인다.
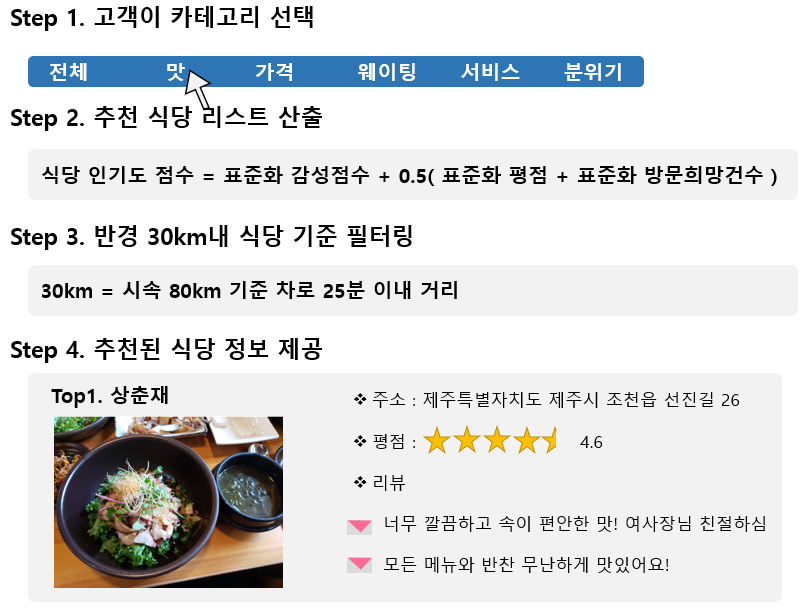
본 게시물은 리뷰기반 식당 추천 리스트를 생성하는 과정으로, 사용한 데이터는 망고플레이트의 제주도 맛집 데이터입니다. 리뷰 기반 감성분석으로 감성점수를 산출하고, [가격, 맛, 서비스, 분위기, 웨이팅] 카테고리별 음식점 추천 리스트를 생성했습니다.
*사용자의 위치를 반영하기 위해 Geocoding을 해서 반경 30Km이내 음식점으로 필터링했습니다.
Geocoding 은 네이버 Api를 이용했으며 R 코딩을 했습니다.
아이디어 구현 과정은 다음과 같습니다.
[목차]
1. 필요한 패키지 설치 및 임포트
2. 망고플레이트 제주도 맛집 링크 수집
3. 망고플레이트 제주도 맛집 식당명, 리뷰, 평점, 주소 등등 수집
4. 맛집 리뷰 형태소분석
5. 맛집 리뷰 단어 빈도 추출
6. Word2Vec과 단어-빈도 행렬을 이용한 리뷰와 카테고리별 연관성 점수 계산
7. 카테고리와 단어의 코사인 유사도 행렬 구하기
8. 단어=문서 행렬 (Term-Document Matrix)
9. 감성분석
10. 생성된 고객 A에 대한 추천리스트
1. 필요한 패키지 설치 및 임포트
!pip3 install beautifulsoup4
import csv
import time
import pandas as pd
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import NoSuchElementException
from selenium import webdriver
import time
import pandas as pd
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
2. 망고플레이트 제주도 맛집 링크 수집
wd = webdriver.Chrome('chromedriver',chrome_options=chrome_options)
wd.get("https://www.mangoplate.com/top_lists/1095_summerguide_jeju")
post_list = []
title_list=[]
for i in range(1,11):
ll = wd.find_element(By.XPATH, "//*[@id='contents_list']/ul/li["+str(i)+"]/div/figure/figcaption/div/span/a").get_attribute('href')
post_list.append(ll)
pageNum = 1
while pageNum < 7:
element=wd.find_element(By.XPATH, '//*[@id="contents_list"]/div/button')
wd.execute_script("arguments[0].click();", element)
time.sleep(1)
for i in range(pageNum*10+1,pageNum*10+11):
try:
ll = wd.find_element(By.XPATH, "//*[@id='contents_list']/ul/li["+str(i)+"]/div/figure/figcaption/div/span/a").get_attribute('href')
post_list.append(ll)
except NoSuchElementException:
print(i)
pageNum += 1
post_infos = pd.DataFrame({'link':post_list})
post_infos.to_csv('data_공모전_link.csv',index=False)
3. 망고플레이트 제주도 맛집 식당명, 리뷰, 평점, 주소 등등 수집
title=[]
review=[]
ID=[]
taste=[]
load=[]
t_1=[] #가고싶다수
t_2=[] #평점
for jj in range(len(post_infos)):
pageNum=0
wd = webdriver.Chrome('chromedriver',chrome_options=chrome_options)
wd.get(post_infos.loc[jj,'link'])
N=wd.find_element(By.XPATH,'/html/body/main/article/div[1]/div[1]/div/section[3]/header/ul/li[1]/button/span').text
if int(N)<=5:
req = wd.page_source
soup=BeautifulSoup(req, 'html.parser')
aa = soup.find_all('p',"RestaurantReviewItem__ReviewText")
bb= soup.find_all('span','RestaurantReviewItem__RatingText')
cc=soup.find_all('span','RestaurantReviewItem__UserNickName')
dd=soup.find('h1','restaurant_name').text
ee=soup.find('div','Restaurant__InfoItemLabel--RoadAddressText').text
ff=soup.find('span','cnt favorite').text
gg=soup.find('strong','rate-point').text
for i in range(len(aa)):
review.append(aa[i].text)
taste.append(bb[i].text)
ID.append(cc[i].text)
title.append(dd)
load.append(ee)
t_1.append(ff)
t_2.append(gg)
if int(N)%5==0:
N_1=int(N)//5-1
else:
N_1=int(N)//5
for _ in range(N_1+1):
element=wd.find_element(By.XPATH, '/html/body/main/article/div[1]/div[1]/div/section[3]/div[2]')
wd.execute_script("arguments[0].click();", element)
time.sleep(3)
req = wd.page_source
soup=BeautifulSoup(req, 'html.parser')
aa = soup.find_all('p',"RestaurantReviewItem__ReviewText")
bb= soup.find_all('span','RestaurantReviewItem__RatingText')
cc=soup.find_all('span','RestaurantReviewItem__UserNickName')
dd=soup.find('h1','restaurant_name').text
ee=soup.find('div','Restaurant__InfoItemLabel--RoadAddressText').text
ff=soup.find('span','cnt favorite').text
gg=soup.find('strong','rate-point').text
for i in range(len(aa)):
review.append(aa[i].text)
taste.append(bb[i].text)
ID.append(cc[i].text)
title.append(dd)
load.append(ee)
t_1.append(ff)
t_2.append(gg)
TOTAL = pd.DataFrame({'review':review, 'ID':ID, 'taste':taste, 'title':title,'load':load, '가고싶다':t_1, '평점':t_2})
for i in range(len(TOTAL['review'])-1):
if TOTAL.loc[i,'review'] in TOTAL.loc[i+1:,'review'].tolist():
print(TOTAL.loc[i,'review'])
TOTAL.to_csv('data_공모전_RAW.csv',index=False)
4. 맛집 리뷰 형태소분석
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
TOTAL=pd.read_csv('/content/drive/MyDrive/data_공모전_RAW_1116.csv',sep=',',encoding="cp949")
import re
okt=Okt()
ii=[]
data_1=TOTAL.dropna(axis=0)
PP=[]
AA=[]
BB=[]
CC=[]
DD=[]
EE=[]
FF=[]
PP_1=[]
for i in range(len(data_1)):
PP.append(data_1.iloc[i,0]) #review
PP_1.append(data_1.iloc[i,0]) #raw
AA.append(data_1.iloc[i,1]) #ID
BB.append(data_1.iloc[i,2]) #title
CC.append(data_1.iloc[i,3]) #taste
DD.append(data_1.iloc[i,4]) #load
EE.append(data_1.iloc[i,5])
FF.append(data_1.iloc[i,6])
for i in range(len(PP)):
PP[i]=re.sub("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]"," ", PP[i])
PP[i]=okt.morphs(PP[i],norm=True, stem=True)
PP[i]=[x for x in PP[i] if len(x)>1]
PP[i]=' '.join(PP[i])
data_2=pd.DataFrame({'review':PP,'ID':AA,'title':BB,'taste':CC,'raw':PP_1,'load':DD,'가고싶다':EE,'평점':FF})
hangul = re.compile('[ㄱ-ㅣ가-힣]+')
for i in range(len(data_2)):
if len(hangul.findall(data_2.iloc[i,0]))>1:
if len(data_2.iloc[i,0])>1:
ii.append(i)
data_3=data_2.iloc[ii,:]
data_3.to_csv('data_공모전_Noun_1116.csv',index=False)
5. 맛집 리뷰 단어 빈도 추출
##단어 빈도 추출 결과, 카테고리: 가격, 맛, 분위기, 서비스, 웨이팅 카테고리를 생성함
A=data_3.review.to_list()
B=[]
for i in range(len(A)):
B+=A[i].split(' ')
words_count={}
for word in B:
if word in words_count:
words_count[word] += 1
else:
words_count[word] = 1
sorted_words = sorted([(k,v) for k,v in words_count.items()], key=lambda word_count: -word_count[1])
print([w[0] for w in sorted_words])
6. Word2Vec과 단어-빈도 행렬을 이용한 리뷰와 카테고리별 연관성 점수 계산
##Word2Vec 카테고리별 코사인 유사도가 높은 단어를 구할 수 있다.
X=[[]]*len(data_3)
for i in range(len(data_3)):
X[i] = data_3.iloc[i,0].split(' ')
from gensim.models import Word2Vec
model_w = Word2Vec(sentences=X,size=500,window=5,min_count=2,workers=4,sg=1)
##카테고리와 단어의 코사인 유사도 행렬을 구할 수 있다.
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
A=pd.read_csv('/content/drive/MyDrive/data_공모전_단어리스트_ver4_1.csv',sep=',',encoding="cp949")
A=A.iloc[:,0].tolist()
A=sorted(A)
B_맛있다=[]
B_가격=[]
B_웨이팅=[]
B_서비스=[]
B_분위기=[]
for i in range(len(A)):
B_맛있다.append(model_w.wv.similarity('맛있다',A[i]))
B_가격.append(model_w.wv.similarity('가격',A[i]))
B_웨이팅.append(model_w.wv.similarity('웨이팅',A[i]))
B_서비스.append(model_w.wv.similarity('서비스',A[i]))
B_분위기.append(model_w.wv.similarity('분위기',A[i]))
B_total=pd.DataFrame({'맛있다':B_맛있다,'가격':B_가격,'웨이팅':B_웨이팅,'서비스':B_서비스,'분위기':B_분위기}).transpose()
B_total.columns=[A]
B_total[B_total<0.8]=0
B_total.to_csv('data_공모전_단어리스트_ver3_1.csv',index=False)
8. 단어=문서 행렬 (Term-Document Matrix)
from sklearn.feature_extraction.text import CountVectorizer
cv=CountVectorizer()
for i in range(len(X)):
globals()['val_{}'.format(i)]=[]
B=[]
for i in range(len(X)):
for j in X[i]:
if j in A:
globals()['val_{}'.format(i)].append(j)
B.append(i)
C=[]
for j in range(len(X)):
if j not in list(set(B)):
C.append('')
else:
C.append(' '.join(globals()['val_{}'.format(j)]))
DTM_array=cv.fit_transform(C).toarray()
feature_names=cv.get_feature_names()
DTM_DataFrame=pd.DataFrame(DTM_array,columns=feature_names)
##카테고리별 리뷰의 연관성을 알 수 있음
import numpy as np
Result=B_total.to_numpy() @ DTM_DataFrame.transpose().to_numpy()
round(pd.DataFrame(Result),4).to_csv('공모전_Relev_결과_1119_2.csv')
B_total.to_csv('공모전_Word2Vec_결과_1119_2.csv')
DTM_DataFrame.to_csv('공모전_DTM_결과_1119_2.csv')
9. 감성분석
##KNU 감성사전에서 팀원과 의논에 음식특화사전을 구축함, lexicon_1_최종사전
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
lexicon=pd.read_csv('/content/drive/MyDrive/lexicon_1_최종사전.csv',sep=',',encoding="cp949")
X=[[]]*len(data_3)
for i in range(len(data_3)):
X[i] = data_3.iloc[i,0].split(' ')
##감성점수를 부여하는 과정
A=[0]*len(data_3)
B=[0]*len(data_3)
C=[0]*len(data_3)
for i in range(len(data_3)):
for j in range(len(X[i])):
if X[i][j] in lexicon.word.tolist():
A[i]+=lexicon.polarity.tolist()[lexicon.word.tolist().index(X[i][j])]
B[i]+=1
for i in range(len(C)):
if B[i]!=0:
C[i]=round(int(A[i])/int(B[i]),2)
data_3[['감성점수']]=C
data_3.to_csv('data_공모전_Sent_1121_1.csv',index=False)
* 데이콘(DACON)에서 주최한 '뉴스 토픽 분류 AI 경진대회' 모형을 공유하고자 게시물을 올렸습니다.
* 이 대회는 특정 모형으로 한국어 뉴스 헤드라인 데이터를 학습한 후 주제를 분류하는 것입니다.
Bi-LSTM 기법을 이용하여 한국어 뉴스 토픽 분류 모형을 만들었습니다. 임베딩은 Fasttext를 사용하였습니다.
먼저 Fasttext 임베딩 코드를 보여드리며 설명한 후 Bi-LSTM 기법을 적용하는 코드를 보여드리며 설명하겠습니다.
*코드는 Google Colaboratory 기준입니다
항목은 다음과 같습니다.
1. 필요한 패키지 설치
2. 데이터 설명 및 전처리
3. Fasttext 이용, 단어를 벡터로 변환
4. Bi-LSTM 기법 적용
그럼 시작하겠습니다.
1. 필요한 패키지 설치
[CODE]
!apt-get update
!apt-get install g++ openjdk-8-jdk python-dev python3-dev
!pip3 install JPype1-py3
!pip3 install konlpy
!JAVA_HOME="C:\Users\tyumi\Downloads"
from konlpy.tag import * #한국어 형태소 분석
okt=Okt()
!pip3 install fasttext #fasttext 설치
import fasttext
import pandas as pd
import re #정규표현식
from tqdm import tqdm_notebook
import numpy as np
from keras.layers import LSTM, Activation, Dropout, Dense, Input,Bidirectional
from keras.layers.embeddings import Embedding
from keras.models import Model
from keras import layers
from keras.callbacks import EarlyStopping
import keras
from keras.models import Sequential
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
2. 데이터 설명 및 전처리
[CODE 2-1]
from google.colab import drive
drive.mount('/content/drive')
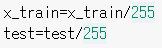
test=pd.read_csv('/content/drive/MyDrive/test_data.csv')
train=pd.read_csv('/content/drive/MyDrive/train_data.csv')
sample_sub=pd.read_csv('/content/drive/MyDrive/sample_submission.csv')
topic_dict=pd.read_csv('/content/drive/MyDrive/topic_dict.csv')
[Explanation 2-1]
[CODE 2-1]은 구글 마운트를 이용해 데이터를 불러오는 과정입니다.
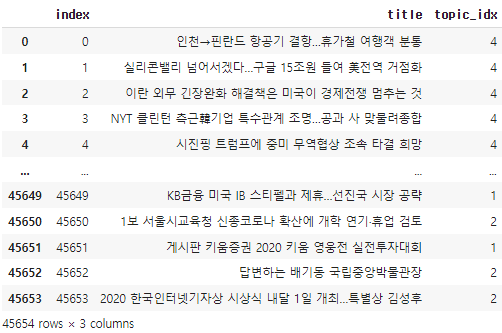
[그림 1] train data[그림 2] 주제
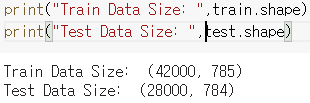
- [그림 1]은 train data 입니다. 45654개의 관측값을 갖고 있는 것을 알 수 있습니다.
- title은 저희가 분석할 뉴스 헤드라인이고 topic_idx는 기사에 할당된 주제입니다.
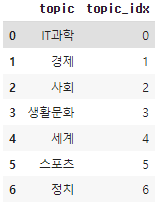
- [그림 2]에 주제에 대한 설명이 있습니다.
- test data는 9131개의 관측값을 갖고 있습니다.
[CODE 2-2]
t_list=[]
for t in range(len(train['title'])):
train['title'][t]=' '.join(re.compile('[가-힣]+').findall(train['title'][t]))
t_list=[]
for t in range(len(test['title'])):
test['title'][t]=' '.join(re.compile('[가-힣]+').findall(test['title'][t]))
for i in range(len(train)):
train['title'][i]=okt.nouns(train['title'][i])
for i in range(len(test)):
test['title'][i]=okt.nouns(test['title'][i])
data_train = train['title']
data_test = test['title']
[Explanation 2-2]
- 정규표현식을 이용하여 train, test data의 title에서 한글을 제외한 나머지를 제거합니다.
- okt를 이용하여 처리된 train, test data의 title에서 명사만 추출합니다.
[그림 3] data_train
- data_train은 [그림 3]과 같습니다. 이로써 각 문장은 명사 단위로 구성된 리스트가 되었습니다.
3. Fasttext 이용, 단어를 벡터로 변환
[CODE 3-1]
with open('/content/drive/MyDrive/data_train.txt', "w") as f:
for i in range(len(data_train)):
f.write(' '.join(data_train.iloc[i])+'\n')
f.close()
with open('/content/drive/MyDrive/data_test.txt', "w") as f:
for i in range(len(data_test)):
f.write(' '.join(data_test.iloc[i])+'\n')
f.close()
model = fasttext.train_unsupervised(input='/content/drive/MyDrive/data_train.txt',model = 'skipgram', lr = 0.05,
dim = 100, ws = 5, epoch = 50,
minn = 1, word_ngrams = 6)
[Explanation 3-1]
[그림 4]data_train
- fasttext 모델의 입력값 형태로 만들기 위해 데이터를 메모장 파일로 저장합니다.([그림 4]와 같습니다.)
- 이후 data_train 파일로 fasttext 모델을 훈련시킵니다. (초모수 설정은 이명호님의 석사 학위 논문 '단어 임베딩과 LSTM을 활용한 비속어 판별 방법'을 참고하였습니다.)
[CODE 3-2]
#정수인덱싱과정
tokenizer = Tokenizer()
tokenizer.fit_on_texts(data_train)
vocab_size=len(tokenizer.word_index)+1
data_train = tokenizer.texts_to_sequences(data_train)
data_test = tokenizer.texts_to_sequences(data_test)
#모든 문장에서 가장 긴 단어 벡터 길이 구하기
max_len=max(len(l) for l in data_train)
#max_len에 맞춰서 패딩하기
X_train = pad_sequences(data_train, maxlen = max_len)
X_test = pad_sequences(data_test, maxlen = max_len)
[Explanation 3-2]
- Tokenizer를 이용해서 data_train/data_test 에 있는 고유한 단어에 번호를 할당합니다.
- 즉, data_train/data_test 를 정수 인덱싱 벡터로 변환하는 것입니다.
- 모든 문장의 단어 벡터 길이는 같아야 됩니다. 같지 않는 경우, 0으로 패딩해서 길이를 맞춰줍니다.
- 따라서 모든 문장에서 최대 단어 벡터 길이를 구한 후 패딩합니다.
[CODE 3-3]
#임베딩행렬 구하기
dd=list(tokenizer.word_index.keys())
embedding_matrix=[np.zeros(shape=(100,),dtype=float)]
for i in range(len(dd)):
embedding_matrix.append(model.get_word_vector(dd[i]))
embedding_matrix=np.array(embedding_matrix)
[Explanation 3-3]
- 학습시킨 fasttext model로 data_train을 구성하는 각 단어의 벡터를 구합니다.
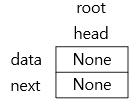
연결 리스트는 데이터를 사슬처럼 연결한 구조입니다. 연결 리스트에서는 각 원소들을 노드라고 부릅니다. 이 노드는 data와 next, pointer 로 구성됩니다. data는 노드의 data, next와 pointer는 뒤쪽 노드(바로 옆에 있는 노드)에 대한 참조를 의미합니다. [그림 1]은 연결 리스트의 기본적인 구조입니다. (연결 리스트 1->3->4 를 나타냈습니다)
[그림 1] 연결 리스트의 구조
[그림 1]을 설명하자면 node A의 뒤쪽 포인터 next 가 node B를 참조하고 node B의 뒤쪽 포인터 next 가 node C를 참조합니다. 그럼 node C의 뒤쪽 포인터는 무엇을 참조할까요? 더이상 참조하는 대상이 없기 때문에 None을 참조합니다.
만약에 node C를 삭제하고 싶다면 어떻게 할가요? 우선 node A부터 node B까지 이동한 후 node B의 뒤쪽 포인터가 None을 참조하면 됩니다. 연결 리스트에서 특정 노드를 찾을 때 또는 특정 노드에 다가가고 싶을 때 처음 노드부터 연결된 순서로 이동해야 됩니다.
2. 머리 노드와 꼬리 노드란?
리스트와 다르게 연결 리스트에는 머리 노드가 존재합니다. 머리 노드는 처음 시작하는 노드입니다.
[그림 1]에서는 머리 노드가 node A이겠죠? 이 머리 노드는 또다른 존재 head에 의해서 선택받은 자입니다.
head는 머리 노드를 참조하는 존재입니다. [그림 1]에서 head는 node A를 참조했으므로 node A가 연결 리스트의 머리 노드입니다.
만약 머리 노드를 새로운 노드 node G로 변경하려면 어떻게 할까요? head가 node G를 참조하여 '얘가 머리 노드이다'라고 선언하면 됩니다. 그리고 node G의 뒤쪽 포인터는 기존의 머리 노드 node A를 참조합니다.
[그림 1] 연결 리스트의 구조
머리 노드가 있으면 꼬리 노드도 있겠죠? node C의 뒤쪽 포인터는 더이상 참조하는 대상이 없기 때문에 None을 참조합니다. 이렇게 뒤쪽 포인터가 더이상 참조하는 게 없는 경우, 해당 노드를 '꼬리 노드' 라고 합니다.
3. 파이썬으로 연결 리스트를 만들어보기
이번에는 연결 리스트를 파이썬에 입력해봅시다.
우선 코드에 대한 설명을 한 후, 1->3->4->5를 입력해보겠습니다.
이후 연결 리스트를 구현하는 다른 방법을 알려드리고 마치겠습니다.
코드 설명
from __future__ import annotations from typing import Any, Type
#연결 리스트용 노드 클래스 class Node:
#첫 번째로 head, data, next, current 초기값을 정의합니다. def __init__(self, data:Any=None, next: Node=None): #초기화 self.data=data #데이터에 대한 참조 self.next=next #뒤쪽 노드에 대한 참조 self.head=None #머리 노드에 대한 참조 self.current=None
#현재 주목하고 있는 노드에 대한 참조(리스트에서 노드를 검색하여, 그 노드를 주목한 직후에 노드를 삭제하는 등의 용도로 사용됩니다.)
#두 번째로 머리 노드를 생성합니다. [그림 2] def add_first(self, data:Any)->None: ptr=self.head
#삽입하기 전의 머리 노드, 저희는 머리 노드를 생성하는 단계이니 None이겠죠? self.head=self.current=Node(data,ptr)
#삽입할 노드 node A를 Node(data,ptr)로 생성합니다.
#해당 노드의 데이터가 data가 되고, 해당 노드의 뒤쪽 포인터가 참조하는 곳은 ptr이 됩니다.
return self.head
[그림 2] 머리 노드 생성 과정
#세 번째로 만들어진 연결 리스트의 끝 노드에 새로운 노드를 삽입합니다. [그림 3]
def add_last(self, data=Any): if self.head is None:
self.add_first(data)
#만약에 head가 없는 경우, 앞에서 정의한 add_first함수로 head를 생성합니다.
else: ptr=self.head
#While문을 이용해서 꼬리 노드를 찾습니다. while ptr.next is not None: ptr=ptr.next
#연결 리스트에서 특정 노드를 찾을 때 무조건 머리 노드부터 하나씩 지나면서 이동합니다.
ptr.next=self.current=Node(data,None) #꼬리 노드를 찾았으면 꼬리 노드 옆에 새로운 node D Node(data,None)를 추가합니다.
#Node(data,None)에서 새로운 node D의 뒤쪽 포인터가 참조하는 것이 None인 이유는
#node D가 곧 꼬리 노드가 되기 때문입니다.
return ptr
[그림 3] node D 추가 과정
구현하기
A=Node() #클래스 할당 A.add_first(1) #머리 노드 지정 (node A) A.add_last(3) #꼬리 노드에 새로운 노드 추가 (node B) A.add_last(4) #꼬리 노드에 새로운 노드 추가 (node C) A.add_last(5) #꼬리 노드에 새로운 노드 추가 (node D)
결과 확인하기 (긴가민가 합니다. 틀리면 바로 댓글 주세요!)
[그림 4] 노드 생성 후 결과
[그림 4]는 앞의 코드 구현한 후 object 항목에서 가져왔습니다. 1->3->4->5가 잘 들어갔는지 확인해보겠습니다.
- 우선 path의 A.head를 봅시다. A.head는 머리 노드 node A를 참조합니다. 따라서 A.head의 data (A.head.data)는 node A의 데이터 1 입니다.
- path의 A.head.next 를 봅시다. A.head.next는 머리 노드 node A의 뒤쪽 포인터가 참조하는 노드입니다. [그림 3]에 따르면 node B겠죠? 마찬가지로 A.head.next의 data (A.head.next.data)는 node B의 데이터 3 입니다.
- path의 A.head.next.next 를 봅시다. A.head.next.next는 node B의 뒤쪽 포인터가 참조하는 노드입니다. [그림 3]에 따르면 node C겠죠? A.head.next.next의 data (A.head.next.next.data)는 node C의 데이터 4 입니다.
- path의 A.head.next.next.next 를 봅시다. A.head.next.next.next는 node C의 뒤쪽 포인터가 참조하는 노드입니다. [그림 3]에 따르면 node D겠죠? A.head.next.next.next의 data (A.head.next.next.next.data)는 node D의 데이터 5 입니다.
로지스틱 회귀의 목적은 종속 변수(Y)와 독립 변수(X) 사이 관계를 구체적인 함수로 나타내서 예측 모델로 사용하는 것입니다. 독립 변수의 선형 결합으로 종속 변수를 설명한다는 관점에서는 선형 회귀 분석과 유사합니다.
*선형 결합: 일차식과 같습니다.
하지만 로지스틱 회귀는 종속 변수가 범주로 구성된 데이터를 대상으로 합니다. 입력 데이터가 주어졌을 때 로지스틱 회귀를 적용한 결과는 특정 분류로 나뉘기 때문에 일종의 분류 기법이라고도 합니다. 종속 변수의 범주가 2개인 경우 로지스틱 회귀라고 부르고 2개 이상인 경우 다항 로지스틱 회귀라고 부릅니다.
이번 시간에 저희는 종속 변수의 범주가 2개인 경우 사용하는 로지스틱 회귀를 공부합니다.
(출처: 위키백과 로지스틱 회귀)
로지스틱 회귀식은 [수식 1] 과 같습니다.
[수식 1] 로지스틱 회귀식
[수식 1]의 (1) 에 따르면 종속 변수 Y가 0과 1의 범주를 가질 때 Y가 1일 확률을 p라고 합니다.
(2)에 따르면 맨 오른쪽 항은 가중치 w1, w2와 편향 b를 입력값 x1, x2와 선형 결합한 일차식입니다.
그럼 확률 p는 어떻게 구할까요? (2)를 풀어낸 결과, 식 (3) 으로 구하는 것을 알 수 있습니다.
2. 로지스틱 회귀를 단일층 신경망으로 구현하기
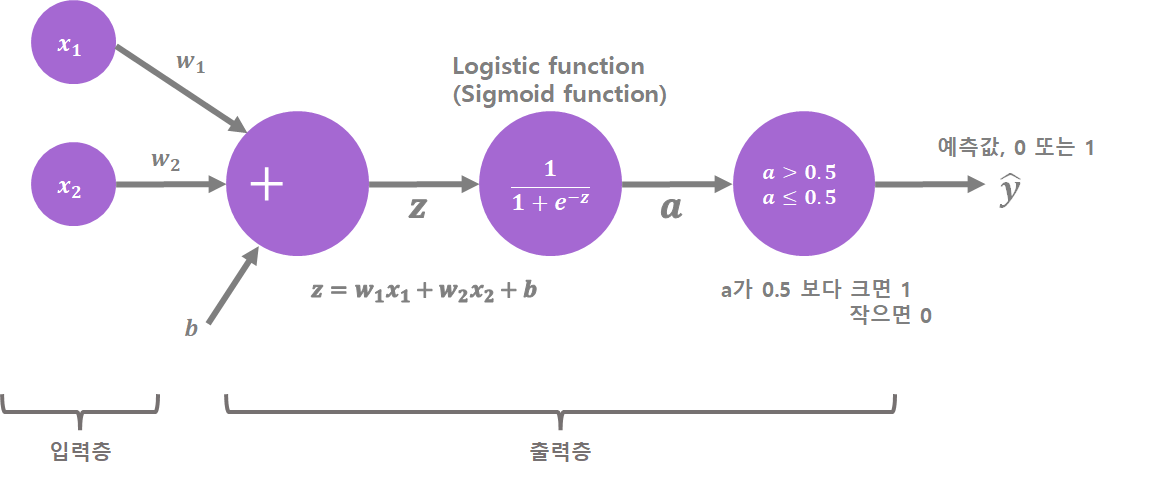
[그림 1]은 로지스틱 회귀를 단일층 신경망으로 구현한 것입니다.
* 단일층 신경망: 은닉층이 없고 입력층과 출력층으로만 구성된 신경망입니다.
로지스틱 회귀에서 저희의 목적은 y가 0인지 1인지 예측하는 것입니다. [수식 1]의 (3)을 이용해서 y가 1인 확률을 구하고 임계 함수를 적용하여 y를 0 또는 1로 분류할 것입니다.
[그림 1] 로지스틱 회귀 단일층 신경망
[그림 1]을 통해 식으로 살펴보았던 로지스틱 회귀가 어떻게 신경망으로 구현되는지 단계별로 설명하겠습니다.
Step1. 입력층에 입력값 x1과 x2가 들어갑니다.
Step2. 출력층에서 입력값들과 가중치 w1, w2 그리고 편향 b을 선형 결합합니다. 그 결과를 z라고 합니다.
Step3. z에 로지스틱 함수를 적용합니다. (이것은 시그모이드 함수라고도 합니다.)
z와 같은 가중합을 출력값 형태인 a로 변환하는 함수를 활성화 함수라고 합니다. 활성화 함수에는 시그모이드
함수, 소프트 맥스 함수 등이 해당됩니다.
* 가중합: 각 입력값과 가중치를 곱한 후 이 결과들과 절편을 합한 것을 의미합니다.
* 활성화 함수: 입력값들의 가중합을 출력값으로 변환하는 함수입니다.
Step4. Step3의 결과로 y=1일 확률이 나오고 이것을 a라고 합니다. 마지막으로 a에 임계함수를 적용하여 0.5보다 크면 1, 작으면 0으로 분류합니다.
이로써 로지스틱 회귀 과정을 알아보았습니다. 그런데 궁금한 점이 하나 있습니다. 가중치와 절편은 어떻게 구할까요?
3번 항목에서 가중치와 절편을 업데이트하는 방법을 차근차근 배워봅시다.
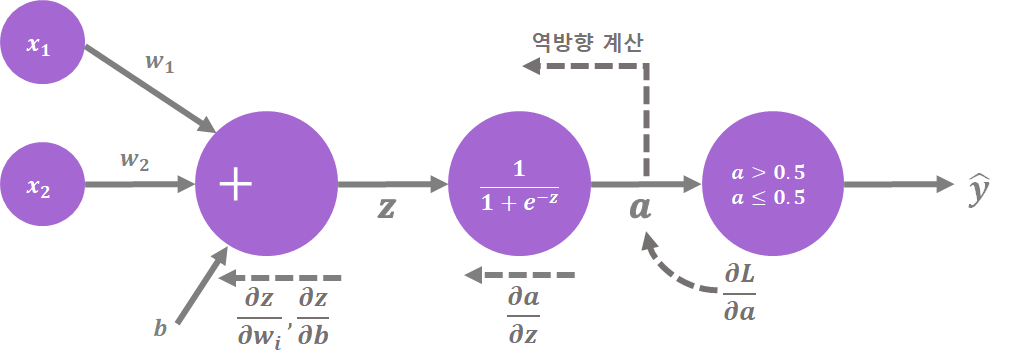
3. 로지스틱 손실 함수를 경사 하강법에 적용하기
로지스틱 회귀와 같이 분류하는 알고리즘의 목표는 무엇일까요? 바로 올바르게 분류된 데이터의 비율을 높이는 것입니다. 그럼 알맞게 분류된 데이터의 비율을 높이는 방향으로 가중치와 절편을 업데이트 해야겠죠? 여기에 꼭 필요한 개념이 있는데요. 바로 손실 함수와 경사 하강법입니다.
* 손실 함수: 예측값과 실제값의 차이를 함수로 정의한 것을 말합니다. 손실 함수는 신경망의 가중치, 절편을 수정하는 기준이되는 함수입니다. 제곱 오차(예측값과 실제값 차이의 제곱합), 크로스 엔트로피 등이 손실 함수로 사용됩니다.
* 경사 하강법: 어떤 손실 함수가 정의되었을 때, 손실 함수의 값이 최소가 되는 지점을 찾아가는 방법입니다.
[그림 2]를 통해 로지스틱 회귀의 가중치와 절편을 업데이트 하는 과정을 단계별로 설명하겠습니다.
CNN은 Convolutional Neural Networks의 줄임말로 알다가도 모르는 기법이다.
그래서 이론을 확실히 하기 위해서 CNN 개념 및 원리를 올려본다.
최대한 알기 쉽게 설명하도록 하겠다. 피드백은 언제나 환영이다. 댓글도 Welcome이다.
이 글의 항목은 아래와 같다.
1. CNN의 NN, Neural Networks(신경망) 이란 무엇인가?
2. CNN이란 무엇인가?
1. CNN의 NN, Neural Networks(신경망) 이란 무엇인가?
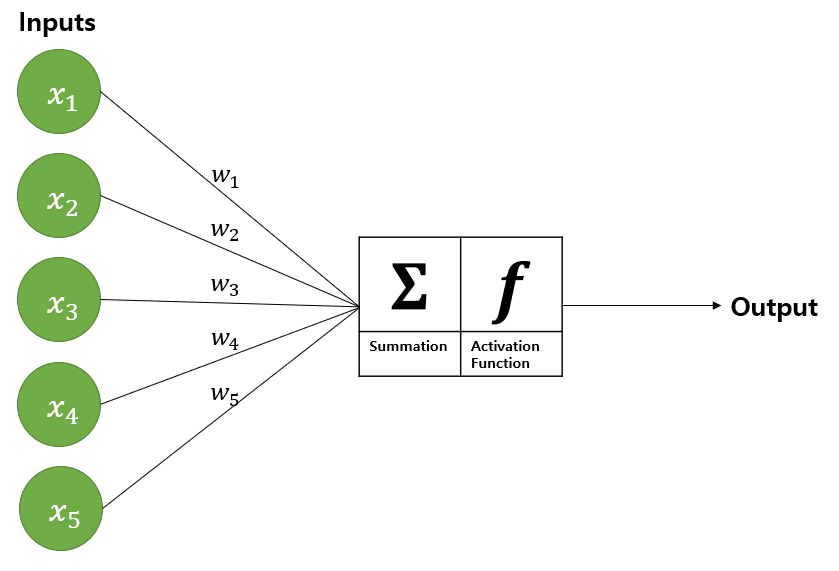
[그림 1]은 신경망의 원리를 잘 보여주는 예시로, 이 예시를 바탕으로 신경망을 설명하겠다.
[그림1] Neural Network 원리
Step.1 Inputs은 데이터를 넣는 곳으로 만약 데이터 [1,2,3,4,5]를 신경망에 넣고 싶으면 Inputs에 [1,2,3,4,5]를 할당하면 된다. (x1=1, x2=2,..., x5=5)
Step.2 w1부터 w5는 가중치이다.가중치와 Inputs의 각 원소를 곱한다.
(x1*w1, x2*w2,..., x5*w5)
Step.3 Step.2에서 구한 가중치와 원소의 곱을모두 합한다.
(x1*w1+x2*w2+...+x5*w5)
Step.4 Step.3에활성화 함수를 씌워서 출력한다. 활성화 함수는 Activation Function이며, 시그모이드, 렐루, 소프트 맥스 등이 사용된다.
2. CNN이란 무엇인가?
2번 섹션은 세 개의 항목으로 나눴다.
2-1. 합성곱(Convolution)을 알아보자
2-2. CNN의 프로세스를 통째로 알아보자
2-3. CNN의 프로세스를 세부적으로 알아보자
1번 섹션에서는 1차원 데이터를 신경망에 적용했다. 그렇다면 이미지와 같은 2차원 데이터는 어떻게 신경망에 적용할까?
정답은 지금부터 알아볼 CNN이다.
CNN은 Convolutional Neural Networks의 약자로, 핵심은 신경망에서 사용된 연산을 합성곱으로 교체한 것이다.
새로운 개념이 나왔다.
합성곱이 무엇일까? 2-1 섹션에서 차근차근 알아보자.
2-1. 합성곱(Convolution)을 알아보자
합성곱은 곱셈과 덧셈으로 이루어진 연산이다.
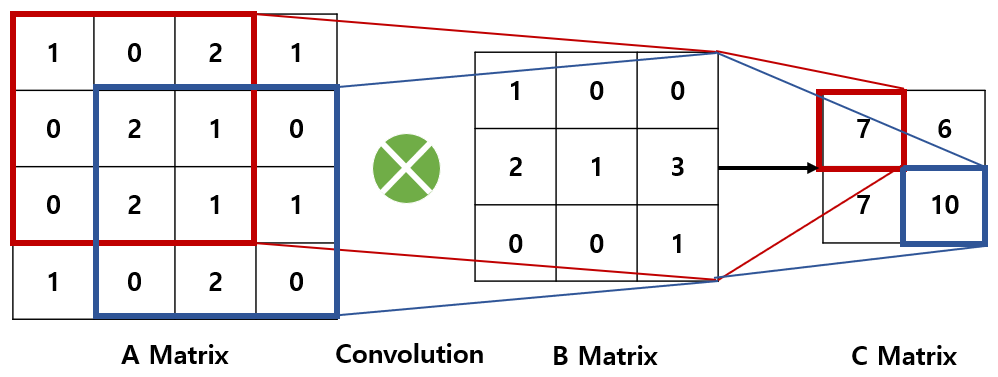
[그림 2]에서 행렬 A와 행렬 B를 합성곱 하여 행렬 C를 만들었다.
행렬 A와 행렬 B의 차원이 다른데 어떻게 곱셈이 가능할까?
정답: 행렬 A 위에서 행렬 B를 이동시키며 겹치는 원소들끼리 곱하고 더한다.
[그림2] 합성곱의 원리
[그림 2]를 단계별로 설명해보겠다.
Step 0. 행렬 A 위에 행렬 B를 올려놓는다.([그림 2]의 빨간색 네모 위에 행렬 B를 올려놓는다)
Step 1. 행렬 A의 빨간색 네모와 행렬 B의 각 원소를 곱하고 모두 더하면행렬 C의 첫 번째 원소 7이 나온다.
(실제 계산: 1*1+0*0+2*0+0*2+2*1+1*3+0*0+2*0+1*1=7)
Step 2. 이제행렬 B를 오른쪽으로 이동시킨다.
행렬 A와 겹치는 부분의 각 원소를 곱하고 모두 더한다. 행렬 C의 두 번째 원소 6이 나온다.
Step 3.이번에는 행렬 B를 대각선 아래로 이동시킨다.
행렬 A와 겹치는 부분의 각 원소를 곱하고 모두 더한다. 행렬 C의 세 번째 원소 7이 나온다.
Step 4.마지막으로 행렬 B를 왼쪽으로 이동시킨다.
[그림 2]에서 행렬 A의 파란색 네모와 행렬 B의 각 원소를 곱하고 모두 더하면 행렬 C의 네 번째 원소 10이 나온다.
Step 5. 이렇게 행렬 B가 행렬 A 위를 다 돌고 나면 행렬 C가 완성된다.이 과정에서 사용된 연산이 바로 합성곱이다.
2-2. CNN의 프로세스를 통째로 알아보자
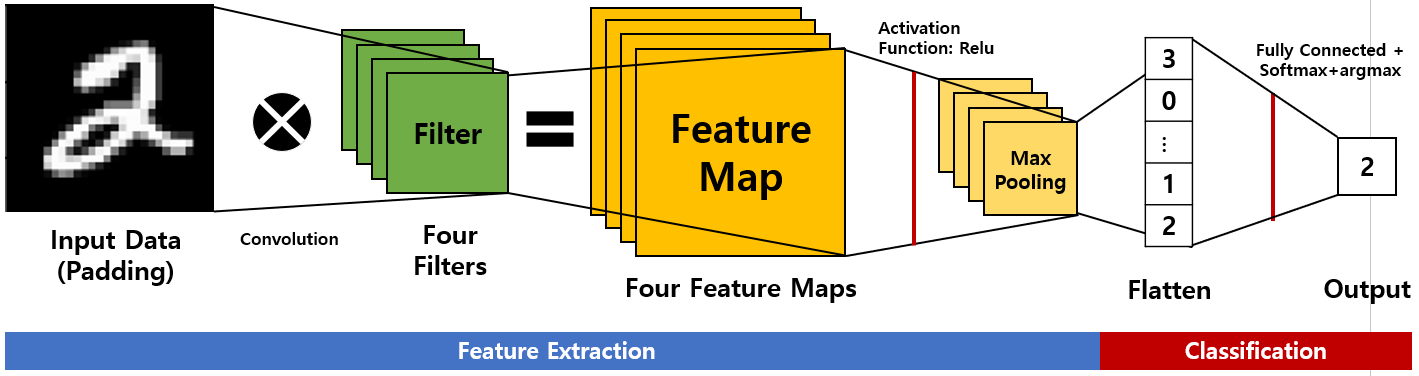
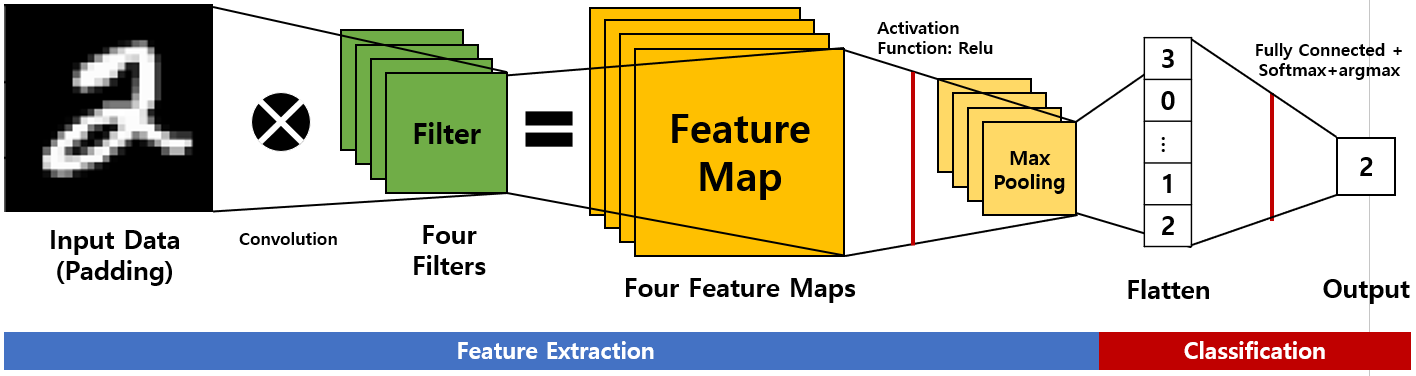
[그림 3]은 CNN의 원리로, 컴퓨터에서 CNN을 통해 이미지를 숫자 2로 분류하는 과정을 보여준다.
[그림 3]으로 CNN의 프로세스를 설명해보겠다.
우선 Input Data에 들어간 이미지 데이터가 가진 특징들을 추출하는 Feature Extraction 작업을 거친다.
이후 자동차 이미지면 자동차, 숫자 2 이미지이면 숫자 2 등으로 분류하는 Classification 작업을 거친다.
[그림 3]은 이미지를 0에서 9 사이의 숫자 중 하나로 분류하는 과정이다.
[그림 3] CNN의 원리
좀 더 알아보자.
Step 1.Image Data에 Padding을 하여 Input Data에 넣는다.여기서 Padding은 '덧댄다'는 의미로, 합성곱 작업을 거치면 결과의 차원이 줄어드는 문제를 방지하기 위하여 Input Data의 모서리에 0이나 다른 숫자를 덧대는 작업을 한다.
(Padding 은 2-3 섹션에서 자세히 알아보자)
Step 2. 특성 맵(Feature map)을 추출하기 위하여Input Data와 Filter를 합성곱(Convolution) 한 후 Relu라는 활성화 함수를 씌운다. [그림 3]에는 네 개의 Filter가 있다. Input Data와 네 개의 Filter를 각각 합성곱 한 후 활성화 함수를 적용하면 네 개의 특성 맵(Feature Maps)이 나온다.
Step 3. Feature Maps의 차원의 복잡성을 줄이면서 유의미한 정보는 유지하기 위해Max Pooling을 이용한다.
Step 5. Step 4의 결과를완전 연결 신경망에 적용한 후 0에서 9 사이의 숫자일 확률을 구하기 위해Softmax 함수를 적용한다. CNN에 입력한 이미지 데이터가 0일 확률부터 9일 확률까지 알 수 있다.
Step 6. Step5의 결과에 최대의 확률을 가진 값을 구하는argmax함수를 적용한다. [그림 3]의 Output에서 2로 분류된 것을 알 수 있다.
2-3. CNN의 프로세스를 세부적으로 알아보자
1) Padding
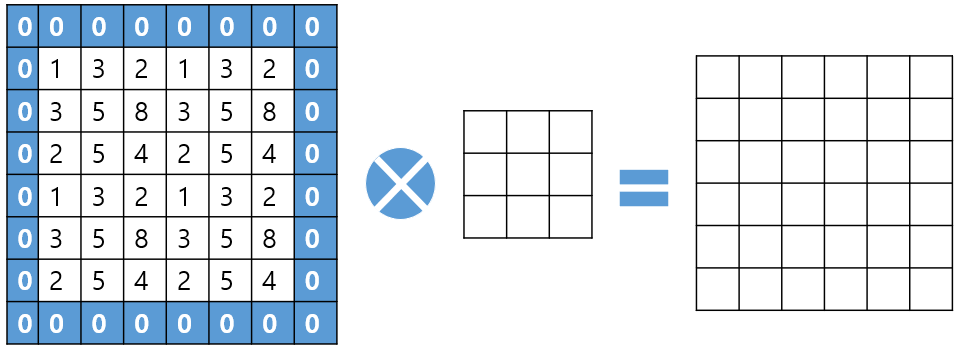
CNN에서 이미지의 특징을 추출하기 위하여 Filter와 합성곱 하는 과정을 거친다.
이후 차원이 축소되면서 정보가 손실되는 경향을 보이는데, 차원이 줄어드는 것을 예방하기 위해 사전 작업으로 이미지 데이터에 Padding(덧대기)를 한다.
[그림 4]는 Padding 예시이다.
[그림4] Padding 예시
Padding은 두 가지 방법이 있다. 하나는 [그림 4]와 같이 데이터의 테두리에 0을 덧대는 방법, 다른 하나는 데이터의 테두리 값을 복사하여 덧대는 방법이 있다.
[그림 4]처럼 테두리에 0을 덧대면 합성곱 이후에도 차원이 유지됨을 알 수 있다.
2) Filters
CNN에서 Input Data와 Filter를 합성곱 한 후 Input Data의 특성 맵(Feature Map)이 추출된다.
Filter가 어떤 값을 가지느냐에 따라서 추출되는 특성 맵이 달라지고 Input Data를 얼마큼의 간격으로 이동하느냐에 따라서도 달라지는데 이 간격을 'Stride'라고 한다. 또한 n개의 Filter를 이용하면 n개의 특성 맵이 추출된다.
참고로 CNN에서 Filter와 Kernel은 같은 의미이다.
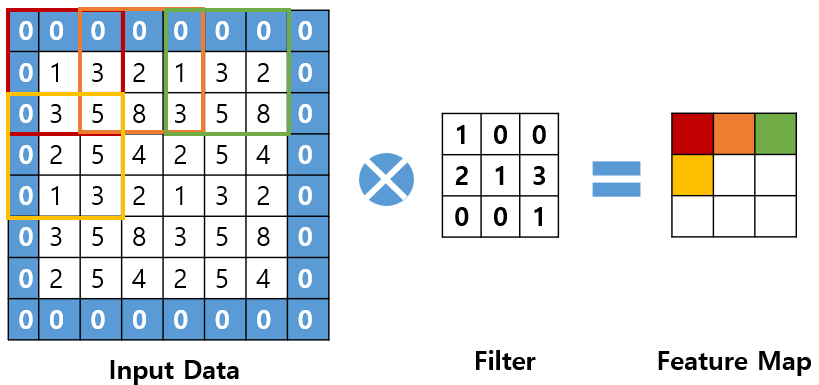
이해를 돕기 위해 [그림 5]를 보며 설명하겠다.
[그림 5] Filter 적용 예시
[그림 5]는 Padding을 씌운 Input Data와 Filter의 합성곱을 나타낸다. 이때 Filter의 수는 한 개라서 하나의 특성 맵이 추출되고 Filter가 Input Data 위를 이동하는 간격은 2이다.
[그림 5]에서 Input Data의 빨간색 네모와 Filter와 연산하여 Feature Map의 빨간 부분이 계산되고 2칸을 이동한 Input Data의 주황색 네모와 Filter와 연산하여 Feature Map의 주황색 부분이 계산된다. 이런 식으로 반복하면 하나의 Feature Map이 완성된다.
3) Pooling
Pooling은 특성 맵을 스캔 하여 최댓값을 고르거나 평균값을 계산하는 것을 의미한다. 보통 연구자들은 최댓값을 고르는 Pooling 방식(Max Pooling)을 선호한다. 그 이유는 Input Data에서 각 Filter가 찾고자 하는 부분은 Feature Map의 가장 큰 값으로 활성화되는데 Max Pooling 방식은 Feature Map의 차원은 줄이면서 유의미한 정보이자, 가장 큰 특징은 유지시키는 성질이 있기 때문이다.
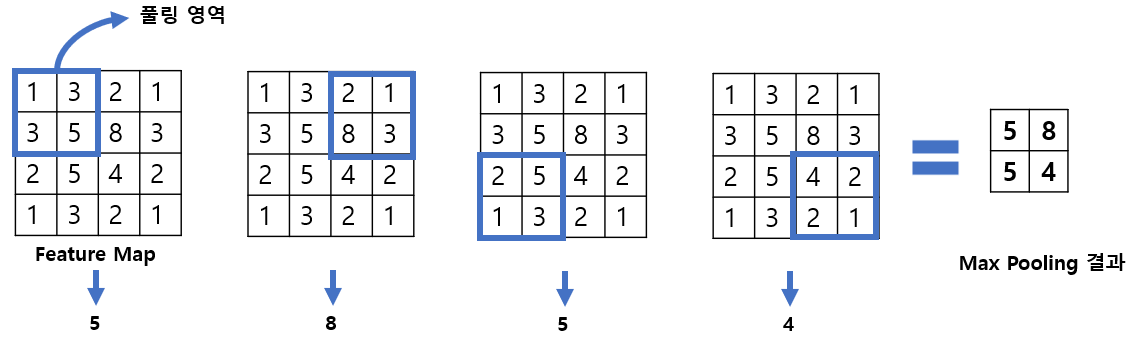
[그림 6]은 Max Pooling의 예시이다.
[그림 6] Max Pooling 예시
하나의 Feature Map이 있으면 이 위를 풀링 영역이 지나가면서 최댓값을 가져온다. 풀링 영역은 사용자가 지정할 수 있으며 보통 2x2를 크기로 지정한다. 그리고 이동 간격(Stride)은 풀링 영역의 한 모서리 크기로 지정한다.
[그림 6]에서 첫 번째 풀링 영역에서 최댓값 5를 뽑아내고 두 칸 이동한 두 번째 풀링 영역에서 최댓값 8을, 왼쪽 대각선 아래로 이동한 세 번째 풀링 영역에서 최댓값 5를, 두 칸 이동한 네 번째 풀링 영역에서 최댓값 4를 뽑아낸다.
다음 게시물에서는 MNIST DATA가 CNN에서 어떻게 굴러가는지 Python 실습을 통해 알아보자